I want to apologize at the top for the general lack-luster appearance and text in this post. It is meant to serve as a quick, simple guide, so I chose to keep it relatively light on text and explanation.
Introduction#
Below, I provide a simple example of a Dirichlet regression in PyMC. This form of generalized linear model is appropriate when modeling proportions of multiple groups, that is, when modeling a collection of positive values that must sum to a constant. Some common examples include ratios and percentages.
For this example, I used a simplified case that was the original impetus for me looking in this form of model. I have measured a protein’s expression in two groups, a control and experimental, across $10$ tissues. I have measured the expression in $6$ replicates for each condition across all $10$ tissues. Therefore, I have $10 \times 6 \times 2$ measurements. The values are all greater than or equal to $0$ (i.e. 0 or positive) and the sum of the values for each replicate sum to $1$.
I want to know if the expression of the protein is different between control and experiment in each tissue.
Because of the constraint on the values being $\ge 0$ and summing to $1$ across replicates, the likelihood should be a Dirichlet distribution. The exponential is the appropriate link function between the likelihood and linear combination of variables.
Setup#
import arviz as az
import janitor # noqa: F401
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import pymc as pm
import seaborn as sns%matplotlib inline
%config InlineBackend.figure_format = 'retina'
sns.set_style("whitegrid")Data generation#
A fake dataset was produced for the situation described above.
The vectors ctrl_tissue_props and expt_tissue_props contain the “true” proportions of protein expression across the ten tissues for the control and experimental conditions.
These were randomly generated as printed at the end of the code block.
N_TISSUES = 10
N_REPS = 6
CONDITIONS = ["C", "E"]
TISSUES = [f"tissue-{i}" for i in range(N_TISSUES)]
REPS = [f"{CONDITIONS[0]}-{i}" for i in range(N_REPS)]
REPS += [f"{CONDITIONS[1]}-{i}" for i in range(N_REPS)]
np.random.seed(909)
ctrl_tissue_props = np.random.beta(2, 2, N_TISSUES)
ctrl_tissue_props = ctrl_tissue_props / np.sum(ctrl_tissue_props)
expt_tissue_props = np.random.beta(2, 2, N_TISSUES)
expt_tissue_props = expt_tissue_props / np.sum(expt_tissue_props)
print("Real proportions for each tissue:")
print(np.vstack([ctrl_tissue_props, expt_tissue_props]).round(3))Real proportions for each tissue:
[[0.072 0.148 0.137 0.135 0.074 0.118 0.083 0.015 0.12 0.098]
[0.066 0.104 0.138 0.149 0.062 0.057 0.098 0.109 0.131 0.086]]
Protein expression values were sampled using these proportions, multiplied by 100 to reduce the variability in the sampled values. Recall that the Dirichlet is effectively a multi-class Beta distribution, so the input numbers can be thought of as the observed number of instances for each class. The more observations, the more confidence that the observed frequencies are representative of the true proportions.
_ctrl_data = np.random.dirichlet(ctrl_tissue_props * 100, N_REPS)
_expt_data = np.random.dirichlet(expt_tissue_props * 100, N_REPS)
expr_data = (
pd
.DataFrame(np.vstack([_ctrl_data, _expt_data]), columns=TISSUES)
.assign(replicate=REPS)
.set_index("replicate")
)
expr_data.round(3)| tissue-0 | tissue-1 | tissue-2 | tissue-3 | tissue-4 | tissue-5 | tissue-6 | tissue-7 | tissue-8 | tissue-9 | |
|---|---|---|---|---|---|---|---|---|---|---|
| replicate | ||||||||||
| C-0 | 0.085 | 0.116 | 0.184 | 0.175 | 0.038 | 0.101 | 0.069 | 0.014 | 0.102 | 0.115 |
| C-1 | 0.134 | 0.188 | 0.101 | 0.119 | 0.075 | 0.104 | 0.052 | 0.001 | 0.121 | 0.107 |
| C-2 | 0.098 | 0.125 | 0.127 | 0.138 | 0.094 | 0.091 | 0.134 | 0.017 | 0.080 | 0.096 |
| C-3 | 0.069 | 0.154 | 0.140 | 0.082 | 0.065 | 0.182 | 0.054 | 0.011 | 0.110 | 0.132 |
| C-4 | 0.033 | 0.208 | 0.151 | 0.090 | 0.067 | 0.109 | 0.064 | 0.003 | 0.160 | 0.115 |
| C-5 | 0.074 | 0.130 | 0.130 | 0.113 | 0.081 | 0.129 | 0.059 | 0.020 | 0.111 | 0.152 |
| E-0 | 0.100 | 0.105 | 0.114 | 0.081 | 0.088 | 0.056 | 0.120 | 0.087 | 0.167 | 0.081 |
| E-1 | 0.043 | 0.124 | 0.184 | 0.098 | 0.071 | 0.040 | 0.122 | 0.071 | 0.157 | 0.089 |
| E-2 | 0.099 | 0.108 | 0.102 | 0.139 | 0.089 | 0.039 | 0.115 | 0.092 | 0.158 | 0.059 |
| E-3 | 0.076 | 0.074 | 0.122 | 0.142 | 0.058 | 0.062 | 0.103 | 0.081 | 0.106 | 0.176 |
| E-4 | 0.098 | 0.103 | 0.117 | 0.113 | 0.048 | 0.110 | 0.113 | 0.104 | 0.166 | 0.027 |
| E-5 | 0.059 | 0.110 | 0.119 | 0.190 | 0.059 | 0.054 | 0.071 | 0.065 | 0.155 | 0.117 |
sns.heatmap(expr_data, vmin=0, cmap="seismic")
plt.show()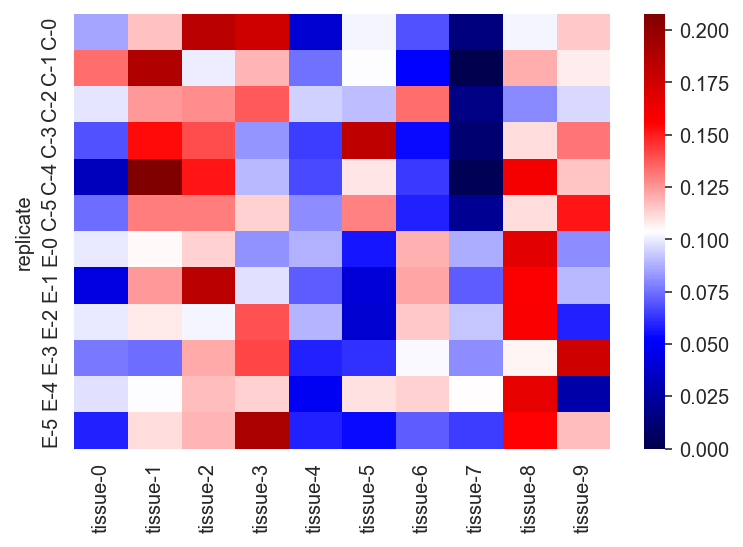
The sum of the values for each replicate should be 1.
expr_data.values.sum(axis=1)
# > array([1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.])array([1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.])
Model#
Model specification#
The model is rather straight forward and immediately recognizable as a generalized linear model. The main attributes are the use of the Dirichlet likelihood and exponential link function. Note, that for the PyMC library, the first dimension contains each “group” of data, that is, the values should sum to $1$ along that axis. In this case, the values of each replicate should sum to $1$.
coords = {"tissue": TISSUES, "replicate": REPS}
intercept = np.ones_like(expr_data)
x_expt_cond = np.vstack([np.zeros((N_REPS, N_TISSUES)), np.ones((N_REPS, N_TISSUES))])
with pm.Model(coords=coords) as dirichlet_reg:
a = pm.Normal("a", 0, 5, dims=("tissue",))
b = pm.Normal("b", 0, 2.5, dims=("tissue",))
eta = pm.Deterministic(
"eta",
a[None, :] * intercept + b[None, :] * x_expt_cond,
dims=("replicate", "tissue"),
)
mu = pm.Deterministic("mu", pm.math.exp(eta), dims=("replicate", "tissue"))
y = pm.Dirichlet("y", mu, observed=expr_data.values, dims=("replicate", "tissue"))
# pm.model_to_graphviz(dirichlet_reg)
dirichlet_reg$$ \begin{array}{rcl} a &\sim & \mathcal{N}(0,~5) \\ b &\sim & \mathcal{N}(0,~2.5) \\ \eta &\sim & \operatorname{Deterministic}(f(a, b)) \\ \mu &\sim & \operatorname{Deterministic}(f(\eta)) \\ y &\sim & \operatorname{Dir}(\mu) \end{array} $$
Sampling#
PyMC does all of the heavy lifting and we just need to press the “Inference Button” with the pm.sample() function.
with dirichlet_reg:
trace = pm.sample(
draws=1000, tune=1000, chains=2, cores=2, random_seed=20, target_accept=0.9
)
_ = pm.sample_posterior_predictive(trace, random_seed=43, extend_inferencedata=True)Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (2 chains in 2 jobs)
NUTS: [a, b]
Sampling 2 chains for 1_000 tune and 1_000 draw iterations (2_000 + 2_000 draws total) took 29 seconds.
Posterior analysis#
Recovering known parameters#
The table below shows the summaries of the marginal posterior distributions for the variables $a$ and $b$ of the model.
real_a = np.log(ctrl_tissue_props * 100)
real_b = np.log(expt_tissue_props * 100) - real_a
res_summary = (
az
.summary(trace, var_names=["a", "b"], hdi_prob=0.89)
.assign(real=np.hstack([real_a, real_b]))
.reset_index()
)
res_summary| index | mean | sd | hdi_5.5% | hdi_94.5% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | real | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | a[tissue-0] | 2.122 | 0.240 | 1.735 | 2.490 | 0.012 | 0.009 | 393.0 | 923.0 | 1.0 | 1.973280 |
| 1 | a[tissue-1] | 2.782 | 0.223 | 2.432 | 3.142 | 0.013 | 0.009 | 309.0 | 657.0 | 1.0 | 2.691607 |
| 2 | a[tissue-2] | 2.691 | 0.231 | 2.349 | 3.082 | 0.013 | 0.009 | 334.0 | 566.0 | 1.0 | 2.618213 |
| 3 | a[tissue-3] | 2.529 | 0.234 | 2.163 | 2.903 | 0.013 | 0.009 | 324.0 | 481.0 | 1.0 | 2.603835 |
| 4 | a[tissue-4] | 2.009 | 0.247 | 1.648 | 2.435 | 0.013 | 0.009 | 399.0 | 586.0 | 1.0 | 2.006772 |
| 5 | a[tissue-5] | 2.538 | 0.231 | 2.180 | 2.906 | 0.013 | 0.009 | 322.0 | 641.0 | 1.0 | 2.465910 |
| 6 | a[tissue-6] | 2.015 | 0.250 | 1.653 | 2.435 | 0.013 | 0.009 | 363.0 | 804.0 | 1.0 | 2.118144 |
| 7 | a[tissue-7] | 0.159 | 0.324 | -0.334 | 0.690 | 0.012 | 0.008 | 828.0 | 1068.0 | 1.0 | 0.407652 |
| 8 | a[tissue-8] | 2.497 | 0.230 | 2.123 | 2.843 | 0.013 | 0.009 | 328.0 | 568.0 | 1.0 | 2.484808 |
| 9 | a[tissue-9] | 2.552 | 0.234 | 2.198 | 2.930 | 0.013 | 0.009 | 333.0 | 688.0 | 1.0 | 2.281616 |
| 10 | b[tissue-0] | 0.010 | 0.335 | -0.507 | 0.549 | 0.016 | 0.011 | 435.0 | 810.0 | 1.0 | -0.089065 |
| 11 | b[tissue-1] | -0.351 | 0.313 | -0.841 | 0.161 | 0.016 | 0.011 | 401.0 | 852.0 | 1.0 | -0.353870 |
| 12 | b[tissue-2] | -0.086 | 0.313 | -0.636 | 0.372 | 0.015 | 0.011 | 413.0 | 680.0 | 1.0 | 0.009744 |
| 13 | b[tissue-3] | 0.065 | 0.318 | -0.445 | 0.560 | 0.016 | 0.011 | 409.0 | 746.0 | 1.0 | 0.099328 |
| 14 | b[tissue-4] | 0.009 | 0.334 | -0.535 | 0.528 | 0.015 | 0.011 | 486.0 | 884.0 | 1.0 | -0.184059 |
| 15 | b[tissue-5] | -0.682 | 0.324 | -1.191 | -0.160 | 0.016 | 0.011 | 433.0 | 743.0 | 1.0 | -0.720852 |
| 16 | b[tissue-6] | 0.437 | 0.331 | -0.082 | 0.987 | 0.016 | 0.011 | 423.0 | 759.0 | 1.0 | 0.162447 |
| 17 | b[tissue-7] | 2.045 | 0.389 | 1.443 | 2.676 | 0.015 | 0.010 | 703.0 | 1041.0 | 1.0 | 1.981890 |
| 18 | b[tissue-8] | 0.298 | 0.306 | -0.189 | 0.795 | 0.016 | 0.011 | 390.0 | 761.0 | 1.0 | 0.085959 |
| 19 | b[tissue-9] | -0.384 | 0.325 | -0.876 | 0.143 | 0.016 | 0.011 | 423.0 | 797.0 | 1.0 | -0.129034 |
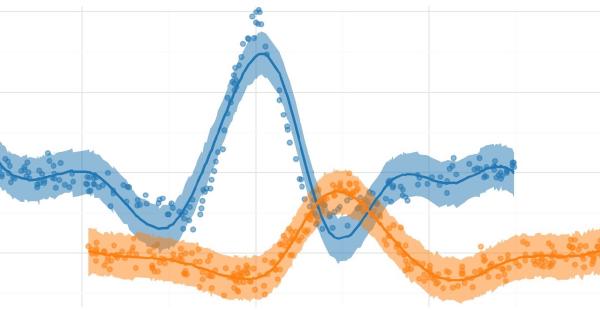
The plot below shows the posterior estimates (blue) against the known proportions (orange).
_, ax = plt.subplots(figsize=(5, 5))
sns.scatterplot(
data=res_summary,
y="index",
x="mean",
color="tab:blue",
ax=ax,
zorder=10,
label="est.",
)
ax.hlines(
res_summary["index"],
xmin=res_summary["hdi_5.5%"],
xmax=res_summary["hdi_94.5%"],
color="tab:blue",
alpha=0.5,
zorder=5,
)
sns.scatterplot(
data=res_summary,
y="index",
x="real",
ax=ax,
color="tab:orange",
zorder=20,
label="real",
)
ax.legend(loc="upper left", bbox_to_anchor=(1, 1))
plt.show()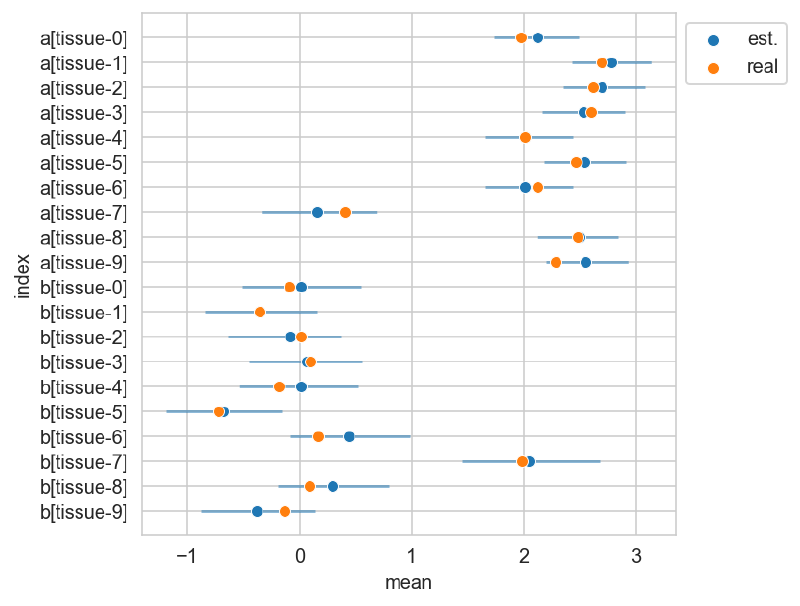
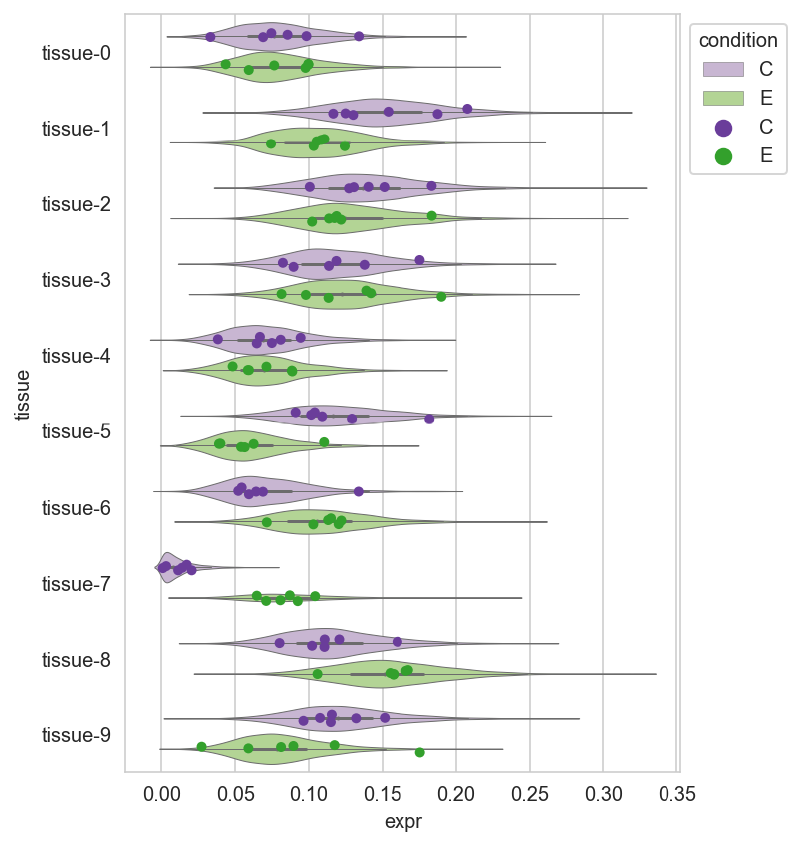
Posterior predictive distribution#
post_pred = (
trace
.posterior_predictive["y"]
.to_dataframe()
.reset_index()
.filter_column_isin("replicate", ["C-0", "E-0"])
.assign(condition=lambda d: [x[0] for x in d["replicate"]])
)
plot_expr_data = (
expr_data
.copy()
.reset_index()
.pivot_longer("replicate", names_to="tissue", values_to="expr")
.assign(condition=lambda d: [x[0] for x in d["replicate"]])
)
violin_pal = {"C": "#cab2d6", "E": "#b2df8a"}
point_pal = {"C": "#6a3d9a", "E": "#33a02c"}
_, ax = plt.subplots(figsize=(5, 7))
sns.violinplot(
data=post_pred,
x="y",
y="tissue",
hue="condition",
palette=violin_pal,
linewidth=0.5,
ax=ax,
)
sns.stripplot(
data=plot_expr_data,
x="expr",
y="tissue",
hue="condition",
palette=point_pal,
dodge=True,
ax=ax,
)
ax.legend(loc="upper left", bbox_to_anchor=(1, 1), title="condition")<matplotlib.legend.Legend at 0x105b11de0>
Session Info#
%load_ext watermark
%watermark -d -u -v -iv -b -h -mLast updated: 2022-11-09
Python implementation: CPython
Python version : 3.10.6
IPython version : 8.4.0
Compiler : Clang 13.0.1
OS : Darwin
Release : 21.6.0
Machine : x86_64
Processor : i386
CPU cores : 4
Architecture: 64bit
Hostname: JHCookMac.local
Git branch: sex-diff-expr-better
matplotlib: 3.5.3
pandas : 1.4.4
numpy : 1.21.6
arviz : 0.12.1
pymc : 4.1.5
janitor : 0.22.0
seaborn : 0.11.2