Introduction#
This was my second round of experimenting with fitting splines in PyMC (note that I used version 4 that is still in beta). In my first post about splines, I went into more depth detailing what a spline is and how to construct the basis and model. Here, I conducted more of an open exploration and experimentation so my comments were limited and mostly aimed to distinguish between the models and describe their pros and cons.
My primary objective for this round was to fit multi-level/hierarchical spline models. I worked up from a single spline fit to a single curve to fitting two curves with a hierarchical model and multivariate normal distribution on the spline parameters.
If you have any follow up questions or recommendations, please email me or leave a comment at the bottom of the post. I am no expert statistical modeler and am still trying to learn about modeling splines in complex models I would greatly appreciate any feedback or suggestions.
Setup#
import re
from dataclasses import dataclass
from pathlib import Path
from typing import Optional
import arviz as az
import janitor # noqa: F401
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import plotnine as gg
import pymc as pm
import pymc.math as pmmath
import scipy.stats as st
import seaborn as sns
from aesara import tensor as at
from patsy import DesignMatrix, build_design_matrices, dmatrix# Set default theme for 'plotnine'.
gg.theme_set(gg.theme_minimal() + gg.theme(figure_size=(8, 4)))
%matplotlib inline
%config InlineBackend.figure_format='retina'
# Constants
RANDOM_SEED = 847
HDI_PROB = 0.89pm.__version__'4.0.0b2'
One group#
To begin, I started with just fitting a single spline to a single curve. For most of this notebook, I used difference of Gaussians to create non-linear curves.
Data#
The data is just a difference of Gaussian curves.
I created the ModelData data class to organize the data and corresponding spline information.
@dataclass
class ModelData:
"""Modeling data."""
data: pd.DataFrame
B: DesignMatrix
knots: np.ndarraydef diff_of_gaussians(
x: np.ndarray,
mus: tuple[float, float],
sds: tuple[float, float],
noise: float,
y_offset: float = 0.0,
) -> pd.DataFrame:
y = (
st.norm.pdf(x, mus[0], sds[0])
- st.norm.pdf(x, mus[1], sds[1])
+ np.random.normal(0, noise, size=len(x))
)
return pd.DataFrame({"x": x, "y": y + y_offset})group_pal = {
"a": "#1F77B4",
"b": "#FF7F0E",
"c": "#2CA02C",
"d": "#D62728",
"e": "#9467BD",
}np.random.seed(RANDOM_SEED)
x = np.random.uniform(-3, 4, 200)
data = diff_of_gaussians(x, (0, 0), (0.3, 1), 0.05, y_offset=10)
sns.scatterplot(data=data, x="x", y="y")
plt.show()
Spline basis#
I used the ‘patsy’ library to build a the B-spline bases used in this notebook.
The dmatrix() function builds a design matrix for the data $x$ using the modeling syntax from R.
I built a wrapper around this function to help keep the various splines I build below consistent.
In some cases, I wanted to include the basis intercept in the design matrix and sometimes I didn’t. The actual parameter was always included in the model, but sometimes I wanted to make it a separate, explicit covariate in the model and other times I wanted to include it in the spline basis. Understanding when to use the spline intercept and when not to took some time, so I tried to describe the logic in the models below.
Below, I built the spline basis for this first simple model and show some descriptive statistics for the knots and spline basis, followed by plotting the basis over the data $x$.
def make_knot_list(data: pd.DataFrame, num_knots: int = 10) -> np.ndarray:
"""Use the quntiles of the data to define knots for a spline."""
return np.quantile(data.x, np.linspace(0, 1, num_knots))
def build_spline(
data: pd.DataFrame,
knot_list: Optional[np.ndarray] = None,
num_knots: int = 10,
intercept: bool = False,
) -> tuple[np.ndarray, DesignMatrix]:
"""Build a spline basis."""
if knot_list is None:
knot_list = make_knot_list(data, num_knots)
B = dmatrix(
f"0 + bs(x, knots=knots, degree=3, include_intercept={intercept})",
{"x": data.x.values, "knots": knot_list[1:-1]},
)
return knot_list, Bknots, B = build_spline(data, intercept=False)
single_curve_data = ModelData(data=data, B=B, knots=knots)single_curve_data.knotsarray([-2.98089976, -2.36504627, -1.67490314, -0.72551484, -0.04744339,
0.50477523, 1.30390392, 2.31655179, 3.43279987, 3.97389701])
single_curve_data.BDesignMatrix with shape (200, 11)
Columns:
['bs(x, knots=knots, degree=3, include_intercept=False)[0]',
'bs(x, knots=knots, degree=3, include_intercept=False)[1]',
'bs(x, knots=knots, degree=3, include_intercept=False)[2]',
'bs(x, knots=knots, degree=3, include_intercept=False)[3]',
'bs(x, knots=knots, degree=3, include_intercept=False)[4]',
'bs(x, knots=knots, degree=3, include_intercept=False)[5]',
'bs(x, knots=knots, degree=3, include_intercept=False)[6]',
'bs(x, knots=knots, degree=3, include_intercept=False)[7]',
'bs(x, knots=knots, degree=3, include_intercept=False)[8]',
'bs(x, knots=knots, degree=3, include_intercept=False)[9]',
'bs(x, knots=knots, degree=3, include_intercept=False)[10]']
Terms:
'bs(x, knots=knots, degree=3, include_intercept=False)' (columns 0:11)
(to view full data, use np.asarray(this_obj))
np.asarray(single_curve_data.B).shape(200, 11)
single_curve_data.data.shape(200, 2)
def plot_spline_basis(model_data: ModelData) -> gg.ggplot:
basis_df = (
pd
.DataFrame(model_data.B)
.reset_index(drop=False)
.assign(x=model_data.data.x.values)
.pivot_longer(index=["index", "x"], names_to="basis", values_to="density")
)
return (
gg.ggplot(basis_df, gg.aes(x="x", y="density", color="basis"))
+ gg.geom_line()
+ gg.geom_vline(xintercept=model_data.knots, color="gray", linetype="--")
+ gg.theme(legend_position="none")
)plot_spline_basis(single_curve_data)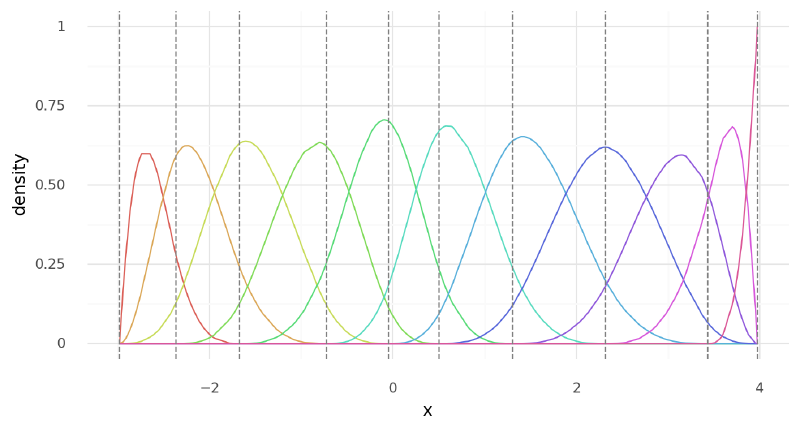
<ggplot: (336642039)>
Model #1#
Again, this is a simple first model with a global intercept $a$ and spline “weights” $\mathbf{w}$. I built the spline basis with 10 knots and without the intercept in the design matrix, instead including the intercept explicitly as $a$. Because I do not include the intercept in the design matrix, there are $N=11$ dimensions on the spline parameter: one between each knot plus one at the end.
$$ \begin{aligned} y &\sim Normal(\mu, \sigma) \\ \mu &= a + \mathbf{B} \mathbf{w}^\text{T} \\ a &\sim N(0, 5) \\ w_n &\sim N(0, 5) \quad \forall i \in {1, …, N} \\ \end{aligned} $$
def build_model1(model_data: ModelData) -> pm.Model:
"""Simple model for a single spline curve."""
df = model_data.data
B = np.asarray(model_data.B)
B_dim = B.shape[1]
with pm.Model(rng_seeder=RANDOM_SEED) as model:
a = pm.Normal("a", 0, 5)
w = pm.Normal("w", 0, 5, shape=B_dim)
mu = pm.Deterministic("mu", a + pmmath.dot(B, w.T))
sigma = pm.Gamma("sigma", 2, 0.5)
y = pm.Normal("y", mu, sigma, observed=df.y)
return modelpm.model_to_graphviz(build_model1(single_curve_data))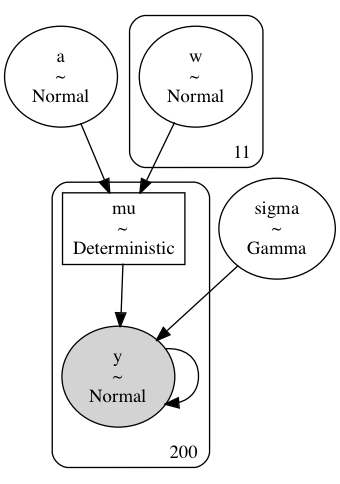
Prior predictive#
To demonstrate the flexibility of the model, I pulled some prior predictive samples from the model and plotted them below. Note how the spline can be shifted vertically – they would instead by fixed near 0 if there was no intercept in the design matrix and no explicit intercept in $\mu$.
def build_new_data(model_data: ModelData, n_x: int = 500) -> ModelData:
"""Build new data for predictions by a model."""
x = model_data.data.x
new_data = pd.DataFrame({"x": np.linspace(x.min(), x.max(), num=n_x)}).assign(y=0)
new_B = build_design_matrices(
[model_data.B.design_info],
{"x": new_data.x.values, "knots": model_data.knots[1:-1]},
)[0]
return ModelData(data=new_data, B=new_B, knots=model_data.knots.copy())def plot_prior(
prior_pred: az.InferenceData, var_name: str, data: pd.DataFrame, alpha: float = 1.0
) -> None:
"""Plot samples from a prior predictive distribution."""
if var_name == "y":
var_prior = prior_pred.prior_predictive[var_name].values
else:
var_prior = prior_pred.prior[var_name].values
var_prior = var_prior.squeeze()
prior_df = (
pd
.DataFrame(var_prior.T)
.reset_index(drop=False)
.assign(x=data.x)
.pivot_longer(["index", "x"], names_to="prior_sample")
.astype({"prior_sample": str})
)
sns.lineplot(
data=prior_df, x="x", y="value", hue="prior_sample", legend=None, alpha=alpha
)
plt.show()new_single_curve_data = build_new_data(single_curve_data)with build_model1(new_single_curve_data):
m1_prior_pred = pm.sample_prior_predictive(samples=10, return_inferencedata=True)Below are the prior samples for $\mu$ across the input range.
plot_prior(m1_prior_pred, "mu", data=new_single_curve_data.data)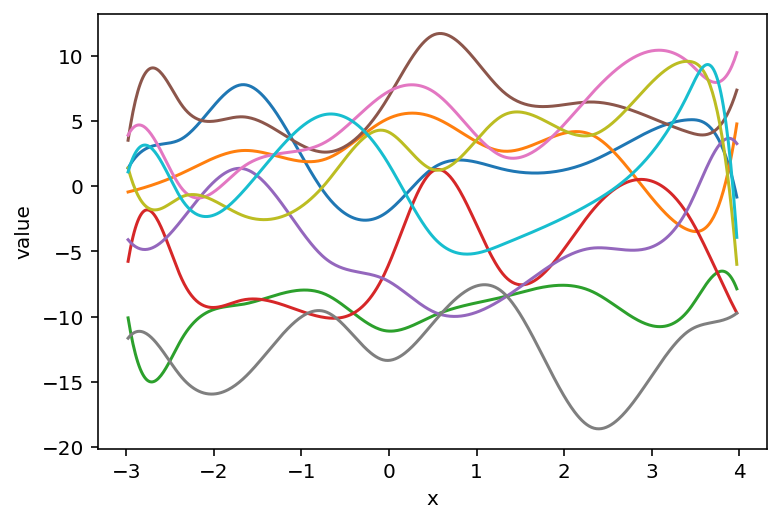
These are the same prior samples, but now including “noise” in the likelihood. These can be thought of as example data that the model would predict before seeing any real data.
plot_prior(m1_prior_pred, "y", data=new_single_curve_data.data, alpha=0.6)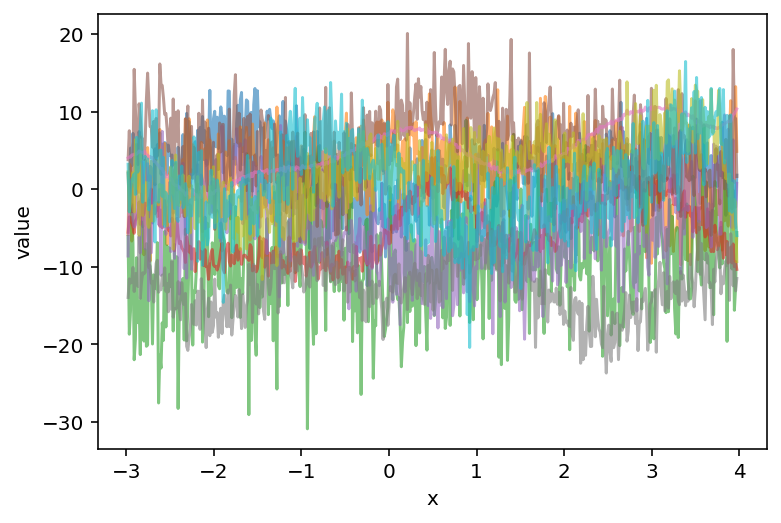
Sample from posterior#
For consistency, I used the sample sampling arguments for PyMC in each of the models (except for some of the more complex models at the end). If I were using these models for a real analysis, I would likely use more tuning and posterior draws and 4 chains, but to speed-up the notebook, I limited them to 500 each and only sampled 2 chains.
pm_sample_kwargs = {
"draws": 500,
"tune": 500,
"chains": 2,
"cores": 2,
"target_accept": 0.95,
"return_inferencedata": True,
}
pm_ppc_kwargs = {
"extend_inferencedata": True,
"progressbar": False,
}with build_model1(single_curve_data):
m1_trace = pm.sample(**pm_sample_kwargs)
pm.sample_posterior_predictive(m1_trace, **pm_ppc_kwargs)Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (2 chains in 2 jobs)
NUTS: [a, w, sigma]
Sampling 2 chains for 500 tune and 500 draw iterations (1_000 + 1_000 draws total) took 24 seconds.
The estimated number of effective samples is smaller than 200 for some parameters.
Posterior analysis#
The posterior distributions for the key parameters in this first model look smooth and there were no divergences.
Some of the $\widehat{R}$ values are a 1.01 or 1.02, but increasing the tuning steps or target_accept would probably fix that at the cost of longer runtime.
az.plot_trace(m1_trace, var_names=["~mu"])
plt.tight_layout()
plt.show()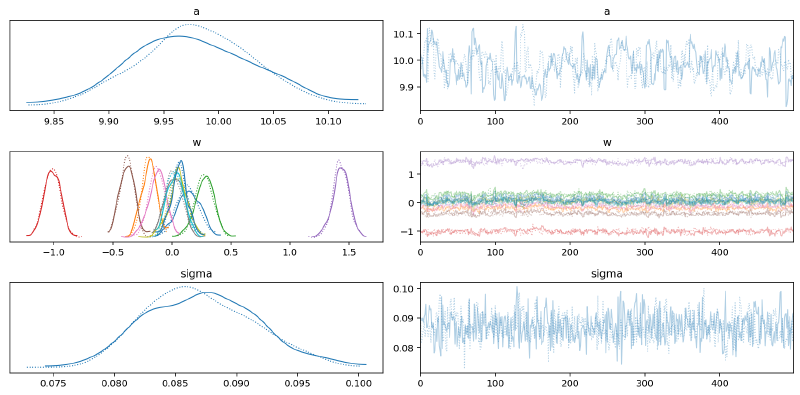
az.plot_parallel(m1_trace, var_names=["w"])
plt.show()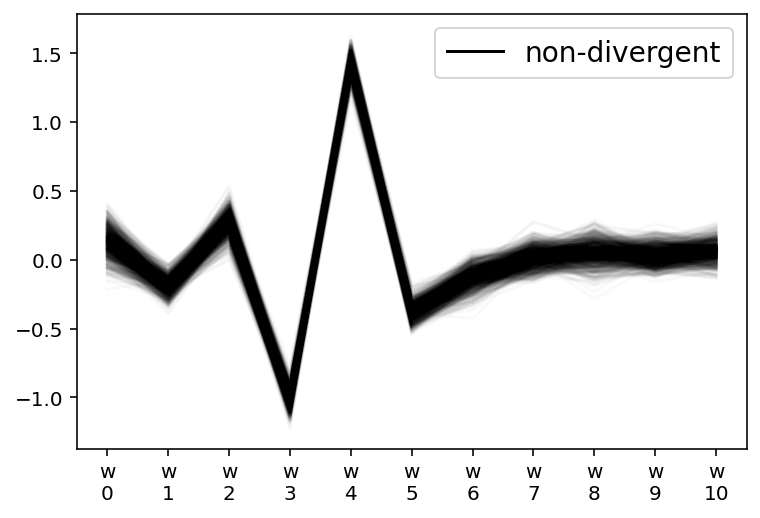
az.summary(m1_trace, var_names=["~mu"])| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| a | 9.979 | 0.054 | 9.886 | 10.084 | 0.004 | 0.003 | 149.0 | 275.0 | 1.01 |
| w[0] | 0.136 | 0.098 | -0.058 | 0.309 | 0.006 | 0.004 | 249.0 | 368.0 | 1.01 |
| w[1] | -0.192 | 0.061 | -0.312 | -0.082 | 0.004 | 0.003 | 236.0 | 411.0 | 1.02 |
| w[2] | 0.275 | 0.080 | 0.133 | 0.429 | 0.005 | 0.003 | 292.0 | 404.0 | 1.00 |
| w[3] | -1.012 | 0.068 | -1.139 | -0.894 | 0.004 | 0.003 | 239.0 | 392.0 | 1.01 |
| w[4] | 1.431 | 0.068 | 1.302 | 1.563 | 0.005 | 0.003 | 212.0 | 376.0 | 1.01 |
| w[5] | -0.379 | 0.062 | -0.492 | -0.267 | 0.004 | 0.003 | 273.0 | 500.0 | 1.01 |
| w[6] | -0.125 | 0.072 | -0.256 | 0.011 | 0.005 | 0.003 | 210.0 | 295.0 | 1.00 |
| w[7] | 0.016 | 0.073 | -0.116 | 0.143 | 0.004 | 0.003 | 320.0 | 758.0 | 1.01 |
| w[8] | 0.053 | 0.081 | -0.098 | 0.207 | 0.005 | 0.003 | 297.0 | 351.0 | 1.00 |
| w[9] | 0.031 | 0.070 | -0.089 | 0.161 | 0.005 | 0.004 | 184.0 | 480.0 | 1.02 |
| w[10] | 0.062 | 0.069 | -0.065 | 0.195 | 0.004 | 0.003 | 287.0 | 383.0 | 1.00 |
| sigma | 0.087 | 0.005 | 0.079 | 0.096 | 0.000 | 0.000 | 697.0 | 669.0 | 1.01 |
az.plot_forest(m1_trace, var_names=["a", "w"], hdi_prob=HDI_PROB)
Below are plots of $\mu$ and posterior predictions across the range of $x$. We can see that this model fit the data fairly well. There is a bit of a discrepancy before the major peak that could be remedied by increasing the number of knots in the spline, but it shall suffice for our purposes here.
def _style_posterior_plot(plot: gg.ggplot) -> gg.ggplot:
return (
plot
+ gg.scale_x_continuous(expand=(0, 0))
+ gg.scale_y_continuous(expand=(0, 0.02))
+ gg.scale_color_manual(group_pal)
+ gg.scale_fill_manual(group_pal)
)
def plot_posterior_mu(
trace: az.InferenceData, data: pd.DataFrame, pt_alpha: float = 0.5
) -> gg.ggplot:
"""Plot posterior distirbution for `mu` alongside the raw data."""
mu_post_df = (
az
.summary(trace, var_names="mu", hdi_prob=HDI_PROB, kind="stats")
.reset_index(drop=True)
.merge(data.copy(), left_index=True, right_index=True)
)
if "k" not in data.columns:
mu_post_df["k"] = "a"
p = (
gg.ggplot(mu_post_df, gg.aes(x="x"))
+ gg.geom_point(gg.aes(y="y", color="k"), alpha=pt_alpha)
+ gg.geom_ribbon(gg.aes(ymin="hdi_5.5%", ymax="hdi_94.5%", fill="k"), alpha=0.5)
+ gg.geom_line(gg.aes(y="mean", color="k"), size=0.5)
)
return _style_posterior_plot(p)plot_posterior_mu(m1_trace, data=single_curve_data.data)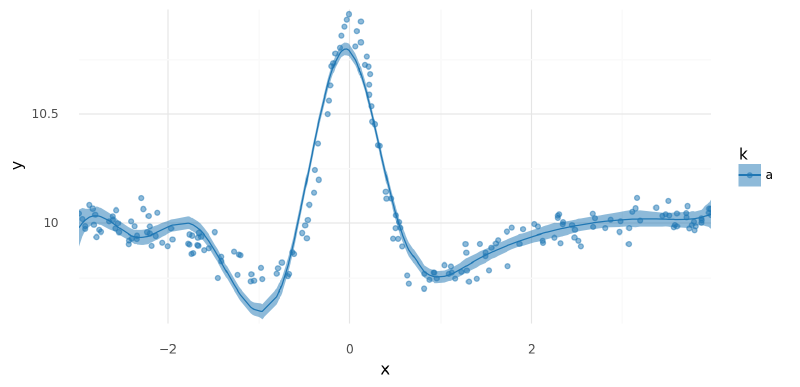
<ggplot: (340754673)>
def summarize_ppc(trace: az.InferenceData, data: pd.DataFrame) -> pd.DataFrame:
"""Summarize a posterior predictive distribution."""
post_pred = trace.posterior_predictive["y"].values.reshape(-1, data.shape[0])
ppc_avg = post_pred.mean(0)
ppc_hdi = az.hdi(post_pred, hdi_prob=HDI_PROB)
ppc_df = data.copy().assign(
post_pred=ppc_avg, hdi_low=ppc_hdi[:, 0], hdi_high=ppc_hdi[:, 1]
)
return ppc_df
def plot_ppc(
ppc_summary: pd.DataFrame, plot_pts: bool = True, pt_alpha: float = 0.5
) -> gg.ggplot:
"""Plot a posterior predictive distribution."""
if "k" not in ppc_summary.columns:
ppc_summary["k"] = np.repeat(["a"], ppc_summary.shape[0])
p = gg.ggplot(ppc_summary, gg.aes(x="x"))
if plot_pts:
p += gg.geom_point(gg.aes(y="y", color="k"), alpha=pt_alpha)
p = (
p
+ gg.geom_ribbon(gg.aes(ymin="hdi_low", ymax="hdi_high", fill="k"), alpha=0.5)
+ gg.geom_line(gg.aes(y="post_pred", color="k"), size=1)
)
return _style_posterior_plot(p)
def summarize_and_plot_ppc(
trace: az.InferenceData,
data: pd.DataFrame,
plot_pts: bool = True,
pt_alpha: float = 0.5,
) -> gg.ggplot:
"""Summarize and plot the posterior predictive distribution."""
ppc_summary = summarize_ppc(trace, data)
return plot_ppc(ppc_summary, plot_pts=plot_pts, pt_alpha=pt_alpha)summarize_and_plot_ppc(m1_trace, single_curve_data.data)/var/folders/r4/qpcdgl_14hbd412snp1jnv300000gn/T/ipykernel_16319/1935723833.py:5: FutureWarning: hdi currently interprets 2d data as (draw, shape) but this will change in a future release to (chain, draw) for coherence with other functions
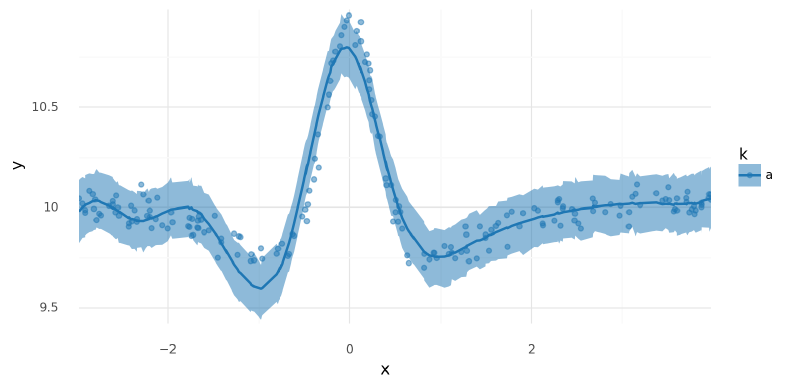
<ggplot: (340754529)>
Comments#
Overall, this first model fit a single curve very well, but we are interested in fitting multiple curves.
Two groups: single set of weights#
Moving closer to the main purpose of this experimentation, we will now build a data set with two curves representing data from two groups or classes $k = {\text{a}, \text{b}}$. Both of the curves are different differences of Gaussians, with a slight vertical shift. I added the vertical shift to force the modeling of a group-specific intercept as well as a global intercept. It is worth noting that managing these intercepts in the models was at times tricky and dependent upon how the spline basis was built. I will describe this more throughout the rest of the notebook.
For this first model with two groups, I will “naively” fit the same model as above (only a single set of spline weights) to demonstrate why we need a multi-level approach.
Data#
Again, the two curves are vertically and horizontally offset difference of Gaussians.
np.random.seed(RANDOM_SEED)
x1 = np.random.uniform(-3, 3, 200)
d1 = diff_of_gaussians(x1, (0, 0), (0.3, 1), 0.05, y_offset=10).assign(k="a")
x2 = np.random.uniform(-3, 3, 300) + 1
d2 = diff_of_gaussians(x2, (1, 1), (0.5, 1), 0.05, y_offset=9.5).assign(k="b")
data = pd.concat([d1, d2]).reset_index(drop=True)
data["k"] = pd.Categorical(data["k"], categories=["a", "b"], ordered=True)
sns.scatterplot(data=data, x="x", y="y", hue="k", palette=group_pal)
plt.show()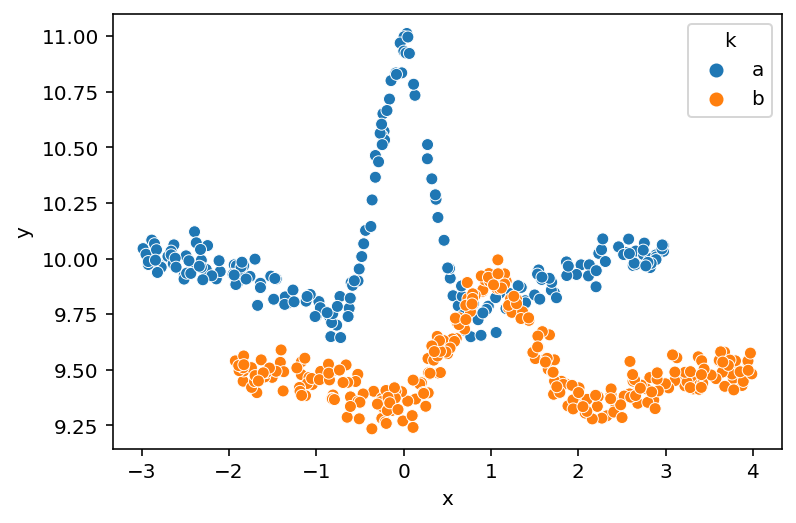
Spline basis#
knots, B = build_spline(data)
two_spline_data = ModelData(data=data.copy(), B=B, knots=knots)Sample from posterior#
with build_model1(two_spline_data):
m1_trace2 = pm.sample(**pm_sample_kwargs)
pm.sample_posterior_predictive(m1_trace2, **pm_ppc_kwargs)Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (2 chains in 2 jobs)
NUTS: [a, w, sigma]
Sampling 2 chains for 500 tune and 500 draw iterations (1_000 + 1_000 draws total) took 22 seconds.
The estimated number of effective samples is smaller than 200 for some parameters.
Posterior analysis#
It is visible from the shapes of the posterior distributions and mixing of the chains that this model did not fit as easily as the first. This is expected because the two curves in the data are quite different from each other, at times moving in different directions.
az.plot_trace(m1_trace2, var_names=["~mu"])
plt.tight_layout()
plt.show()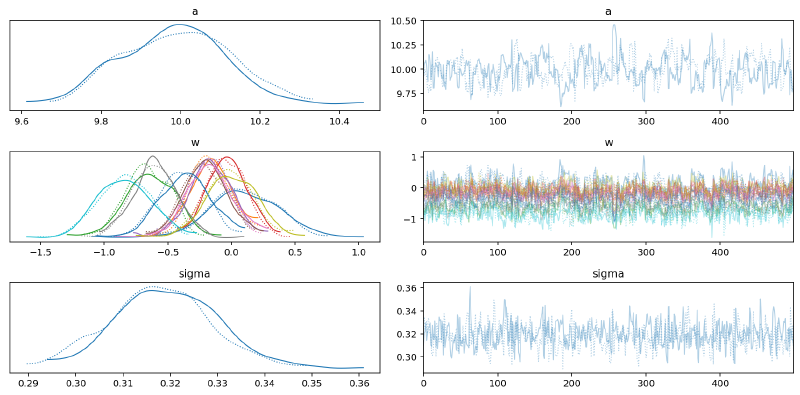
From the parallel plot below, we can see that $w_{3-6}$ had a higher level of uncertainty. This is because this is where the two curves are most different and at odds with each other.
az.plot_parallel(m1_trace2, var_names=["w"])
plt.show()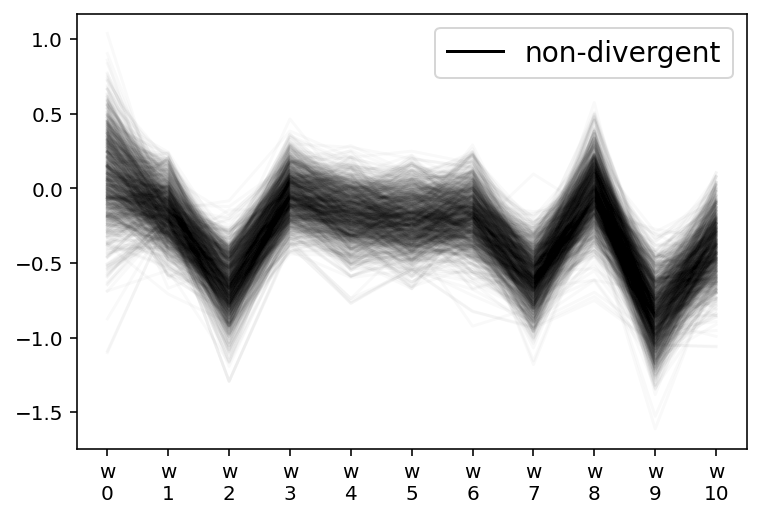
az.plot_forest(m1_trace2, var_names="w", hdi_prob=HDI_PROB, combined=True)
plt.show()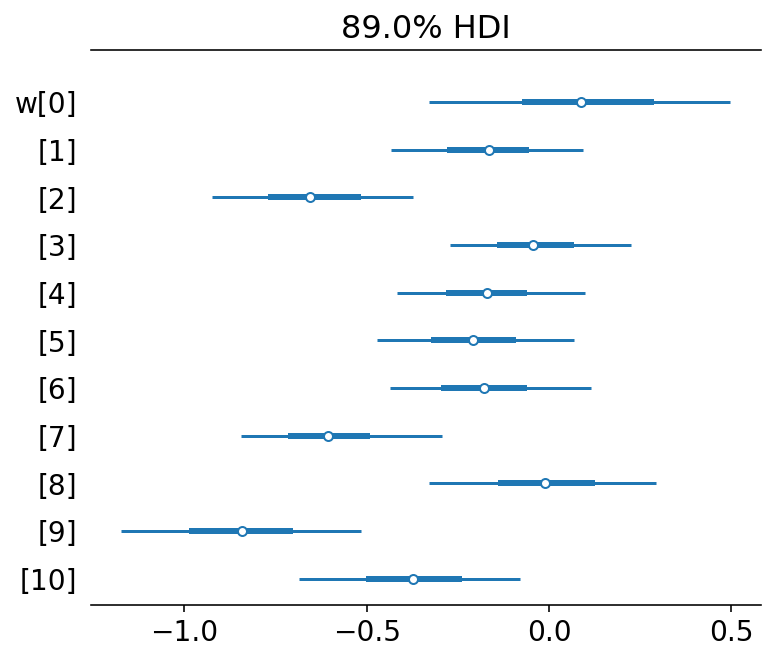
az.summary(m1_trace2, var_names=["~mu"])| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| a | 9.989 | 0.138 | 9.734 | 10.231 | 0.010 | 0.007 | 181.0 | 339.0 | 1.01 |
| w[0] | 0.095 | 0.271 | -0.384 | 0.605 | 0.018 | 0.013 | 226.0 | 415.0 | 1.01 |
| w[1] | -0.164 | 0.163 | -0.456 | 0.162 | 0.007 | 0.005 | 525.0 | 682.0 | 1.00 |
| w[2] | -0.651 | 0.184 | -0.999 | -0.331 | 0.012 | 0.009 | 230.0 | 354.0 | 1.01 |
| w[3] | -0.037 | 0.155 | -0.337 | 0.247 | 0.010 | 0.007 | 253.0 | 404.0 | 1.00 |
| w[4] | -0.174 | 0.164 | -0.512 | 0.102 | 0.010 | 0.007 | 250.0 | 415.0 | 1.01 |
| w[5] | -0.209 | 0.168 | -0.510 | 0.122 | 0.011 | 0.008 | 237.0 | 516.0 | 1.00 |
| w[6] | -0.180 | 0.176 | -0.511 | 0.138 | 0.011 | 0.008 | 276.0 | 378.0 | 1.01 |
| w[7] | -0.605 | 0.170 | -0.928 | -0.295 | 0.010 | 0.007 | 274.0 | 542.0 | 1.01 |
| w[8] | -0.012 | 0.197 | -0.382 | 0.343 | 0.010 | 0.008 | 366.0 | 511.0 | 1.00 |
| w[9] | -0.842 | 0.205 | -1.198 | -0.451 | 0.010 | 0.007 | 388.0 | 557.0 | 1.00 |
| w[10] | -0.374 | 0.193 | -0.705 | -0.001 | 0.012 | 0.009 | 246.0 | 382.0 | 1.01 |
| sigma | 0.319 | 0.011 | 0.299 | 0.339 | 0.000 | 0.000 | 627.0 | 585.0 | 1.01 |
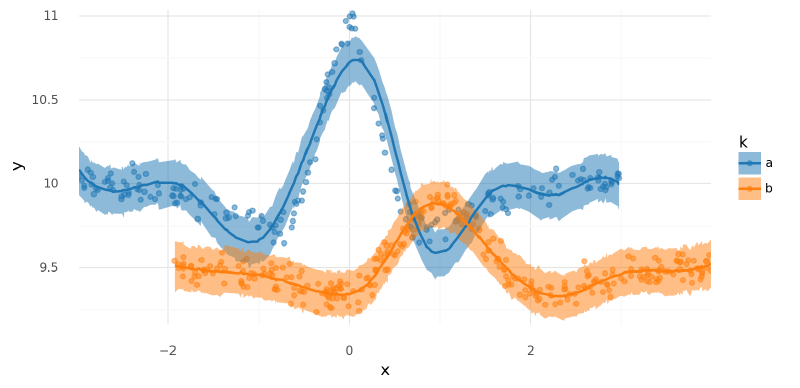
The model just took the average of the two curves (“split the baby”).
plot_posterior_mu(m1_trace2, data=two_spline_data.data)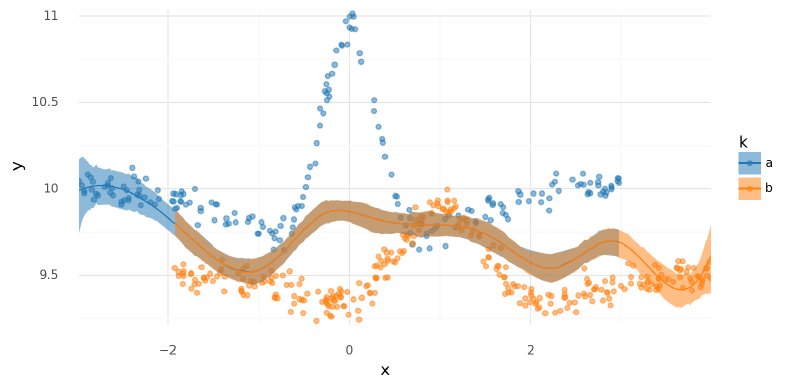
<ggplot: (339788782)>
summarize_and_plot_ppc(m1_trace2, two_spline_data.data)/var/folders/r4/qpcdgl_14hbd412snp1jnv300000gn/T/ipykernel_16319/1935723833.py:5: FutureWarning: hdi currently interprets 2d data as (draw, shape) but this will change in a future release to (chain, draw) for coherence with other functions
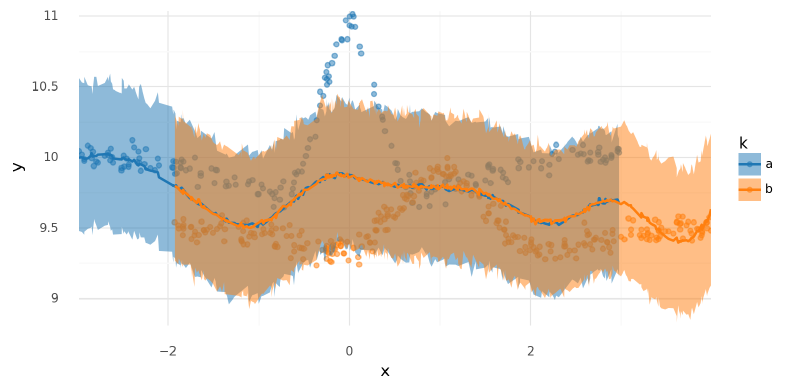
<ggplot: (339219890)>
Comments#
The purpose of this initial demonstration of fitting two distinct curves with a single set of spline weights was to motivate the following models that include a set of weights per group $k$.
Two groups: separate spline bases and per-group weights#
One way to jointly model multiple curves is to build a separate spline basis per group and include separate spline weights per group in the model. This technically works, but has some drawbacks I discussed afterwards.
Spline basis#
For this model, a distinct spline basis was created for each group.
Notably, each spline basis has a different set of knots (though the same number) – this helps substantially with model fit.
To implement this, I basically treated the groups as separate data sets and built ModelData objects for them separately.
I decided to not include the intercepts in each spline and instead model them explicitly as $\bf{a}$ in the model. I think it would have been more or less equivalent to include the spline intercepts in the design matrices and then add a single global intercept $a$ in the model.
multi_model_data: list[ModelData] = []
for k in two_spline_data.data.k.unique():
data_k = two_spline_data.data.copy().query(f"k=='{k}'").reset_index(drop=True)
knots_k, B_k = build_spline(data_k)
md = ModelData(data=data_k, B=B_k, knots=knots_k)
multi_model_data.append(md)
print(len(multi_model_data))2
for md in multi_model_data:
print(md.B.shape)(200, 11)
(300, 11)
def stack_splines(datas: list[ModelData]) -> np.ndarray:
"""Stack the spline arrays from a collection of ModelData."""
return np.vstack([np.asarray(md.B) for md in datas])
def stack_data(datas: list[ModelData]) -> pd.DataFrame:
"""Stack the data from a collection of ModelData."""
return pd.concat([md.data for md in datas]).reset_index(drop=True)
stacked_B = stack_splines(multi_model_data)
stacked_data = stack_data(multi_model_data)
basis_df = (
pd
.DataFrame(stacked_B)
.assign(k=stacked_data.k.values, x=stacked_data.x.values)
.pivot_longer(["k", "x"], names_to="basis", values_to="density")
.assign(basis=lambda d: [f"{k}: {x}" for x, k in zip(d.basis, d.k)])
)
(
gg.ggplot(basis_df, gg.aes(x="x", color="k"))
+ gg.geom_line(gg.aes(group="basis", y="density"), alpha=0.5, size=1)
+ gg.geom_rug(data=stacked_data, alpha=0.5, sides="b")
+ gg.scale_color_manual(values=group_pal)
)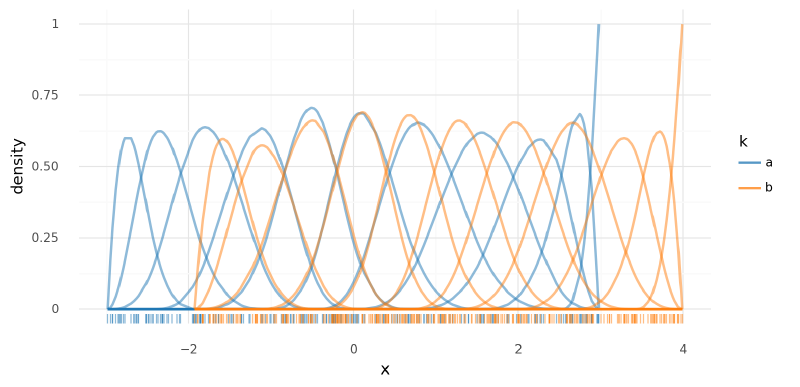
<ggplot: (339223266)>
Model #2#
In theory, I could use a different number of knots per spline basis, but I forced them to have the same number of knots so I could have a 2-dimensional ($K$ knots $\times$ $N$ groups) variable $\bf{w}$.
$$ \begin{aligned} y &\sim N(\mu, \sigma) \\ \mu_k &= \mathbf{a}_k + \mathbf{B}_k \mathbf{w}_k^\text{T} \\ a_k &\sim N(0, 5) \quad \forall k \in K \\ w _ {i,k} &\sim N(0, 2) \quad \forall k \in K, \forall i \in {1, \dots, N} \end{aligned} $$
def build_model2(datas: list[ModelData]) -> pm.Model:
"""Model separate splines."""
y_hat = np.mean([d.data.y.mean() for d in datas])
B_dim = datas[0].B.shape[1]
for md in datas:
assert md.B.shape[1] == B_dim, "Splines have different number of features."
B_k = [np.asarray(md.B) for md in datas]
df = stack_data(datas)
k = df.k.cat.codes.values.astype(int)
n_k = len(df.k.cat.categories)
with pm.Model(rng_seeder=RANDOM_SEED) as model:
a = pm.Normal("a", y_hat, 5, shape=n_k)
w = pm.Normal("w", 0, 2, shape=(B_dim, n_k))
_mu = []
for i in range(n_k):
_mu.append(pmmath.dot(B_k[i], w[:, i]).reshape((-1, 1)))
mu = pm.Deterministic("mu", a[k] + at.vertical_stack(*_mu).squeeze())
sigma = pm.Gamma("sigma", 2, 0.5)
y = pm.Normal("y", mu, sigma, observed=df.y.values)
return modelm2 = build_model2(multi_model_data)
pm.model_to_graphviz(m2)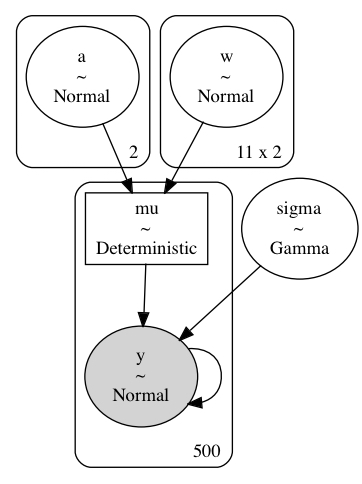
Sample from posterior#
with build_model2(multi_model_data):
m2_trace = pm.sample(**pm_sample_kwargs)
pm.sample_posterior_predictive(m2_trace, **pm_ppc_kwargs)Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (2 chains in 2 jobs)
NUTS: [a, w, sigma]
Sampling 2 chains for 500 tune and 500 draw iterations (1_000 + 1_000 draws total) took 38 seconds.
Posterior analysis#
The model actually fits very well. This shouldn’t be surprising though because it is effectively just two duplicates of the first model, one for each curve. The parameters are not linked in any way (other than $\sigma$ which is the same value here anyways).
az.plot_trace(m2_trace, var_names=["~mu"])
plt.tight_layout()
plt.show()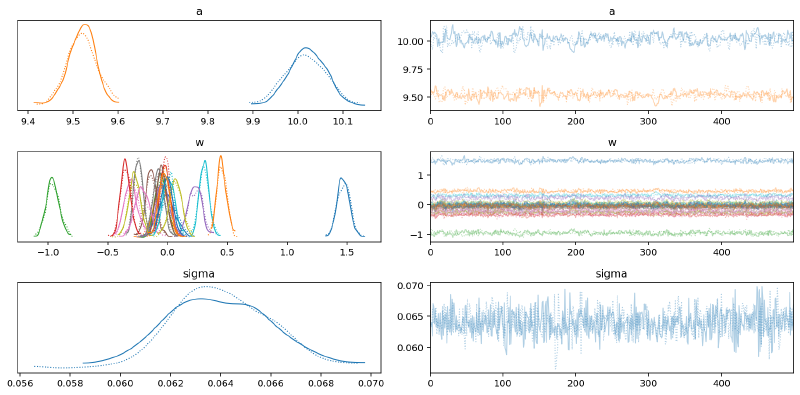
az.summary(m2_trace, var_names=["~mu"], hdi_prob=HDI_PROB)| mean | sd | hdi_5.5% | hdi_94.5% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| a[0] | 10.019 | 0.043 | 9.955 | 10.090 | 0.003 | 0.002 | 282.0 | 400.0 | 1.00 |
| a[1] | 9.519 | 0.032 | 9.469 | 9.572 | 0.002 | 0.001 | 308.0 | 343.0 | 1.00 |
| w[0, 0] | -0.008 | 0.080 | -0.126 | 0.124 | 0.004 | 0.003 | 344.0 | 447.0 | 1.01 |
| w[0, 1] | -0.055 | 0.062 | -0.159 | 0.035 | 0.003 | 0.002 | 372.0 | 437.0 | 1.00 |
| w[1, 0] | -0.054 | 0.046 | -0.133 | 0.015 | 0.002 | 0.002 | 460.0 | 737.0 | 1.00 |
| w[1, 1] | -0.019 | 0.040 | -0.085 | 0.042 | 0.002 | 0.001 | 677.0 | 750.0 | 1.00 |
| w[2, 0] | -0.038 | 0.061 | -0.132 | 0.059 | 0.003 | 0.002 | 414.0 | 414.0 | 1.00 |
| w[2, 1] | -0.139 | 0.048 | -0.218 | -0.069 | 0.002 | 0.002 | 430.0 | 472.0 | 1.01 |
| w[3, 0] | -0.306 | 0.054 | -0.392 | -0.222 | 0.003 | 0.002 | 381.0 | 629.0 | 1.00 |
| w[3, 1] | -0.245 | 0.038 | -0.309 | -0.188 | 0.002 | 0.001 | 446.0 | 471.0 | 1.00 |
| w[4, 0] | -0.274 | 0.052 | -0.354 | -0.189 | 0.003 | 0.002 | 363.0 | 517.0 | 1.00 |
| w[4, 1] | 0.305 | 0.042 | 0.243 | 0.374 | 0.002 | 0.001 | 434.0 | 460.0 | 1.01 |
| w[5, 0] | 1.472 | 0.052 | 1.388 | 1.551 | 0.003 | 0.002 | 389.0 | 538.0 | 1.00 |
| w[5, 1] | 0.453 | 0.040 | 0.385 | 0.513 | 0.002 | 0.001 | 425.0 | 460.0 | 1.00 |
| w[6, 0] | -0.960 | 0.054 | -1.050 | -0.875 | 0.003 | 0.002 | 373.0 | 526.0 | 1.01 |
| w[6, 1] | -0.352 | 0.042 | -0.421 | -0.290 | 0.002 | 0.001 | 445.0 | 464.0 | 1.00 |
| w[7, 0] | 0.231 | 0.059 | 0.132 | 0.315 | 0.003 | 0.002 | 408.0 | 673.0 | 1.00 |
| w[7, 1] | -0.052 | 0.042 | -0.121 | 0.013 | 0.002 | 0.001 | 420.0 | 570.0 | 1.00 |
| w[8, 0] | -0.213 | 0.062 | -0.307 | -0.111 | 0.003 | 0.002 | 486.0 | 351.0 | 1.00 |
| w[8, 1] | -0.076 | 0.047 | -0.151 | -0.005 | 0.002 | 0.002 | 492.0 | 454.0 | 1.00 |
| w[9, 0] | 0.066 | 0.054 | -0.019 | 0.155 | 0.003 | 0.002 | 407.0 | 535.0 | 1.00 |
| w[9, 1] | 0.010 | 0.049 | -0.073 | 0.086 | 0.002 | 0.001 | 605.0 | 647.0 | 1.00 |
| w[10, 0] | -0.007 | 0.053 | -0.088 | 0.082 | 0.003 | 0.002 | 366.0 | 456.0 | 1.00 |
| w[10, 1] | -0.028 | 0.046 | -0.105 | 0.034 | 0.002 | 0.002 | 446.0 | 585.0 | 1.00 |
| sigma | 0.064 | 0.002 | 0.061 | 0.067 | 0.000 | 0.000 | 1222.0 | 545.0 | 1.00 |
We can see that the intercept $\mathbf{a}$ has done its job by acting as a group-varying intercept allowing $\mathbf{w}$ to represent deviations from there.
az.plot_forest(m2_trace, var_names=["a"], hdi_prob=HDI_PROB, combined=True)
plt.show()
az.plot_forest(m2_trace, var_names=["w"], hdi_prob=HDI_PROB, combined=True)
plt.show()
From the plots of $\mu$ and the posterior predictive distribution below, this model fits the data very well.
plot_posterior_mu(m2_trace, data=stacked_data)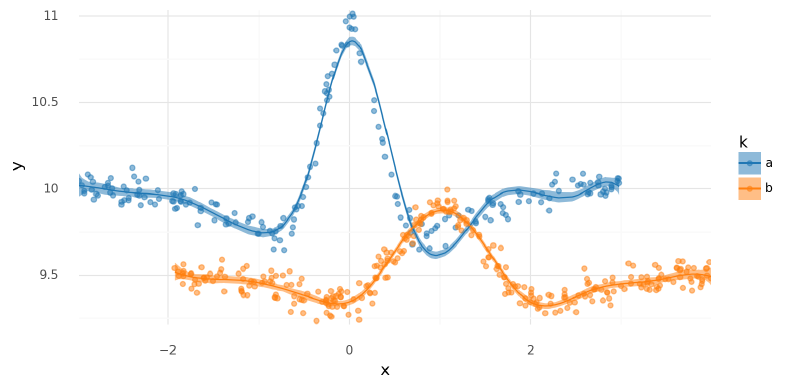
<ggplot: (339553344)>
summarize_and_plot_ppc(m2_trace, stacked_data)/var/folders/r4/qpcdgl_14hbd412snp1jnv300000gn/T/ipykernel_16319/1935723833.py:5: FutureWarning: hdi currently interprets 2d data as (draw, shape) but this will change in a future release to (chain, draw) for coherence with other functions
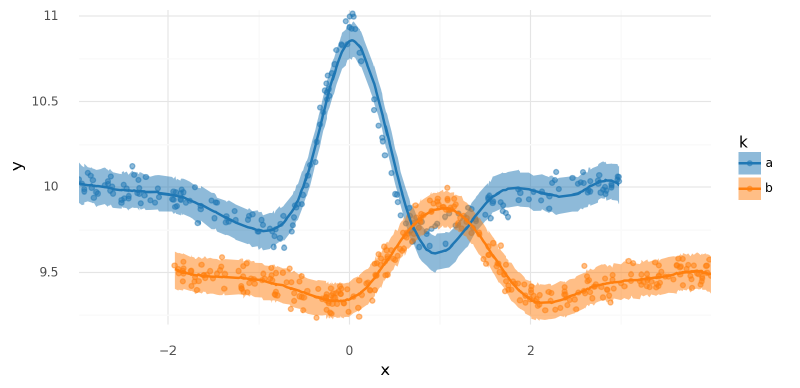
<ggplot: (340756836)>
Comments#
This model could suffice for many models dependent on the needs of the problem and the proposed data-generation process. It fits quickly and well.
There are two main limitations of this approach:
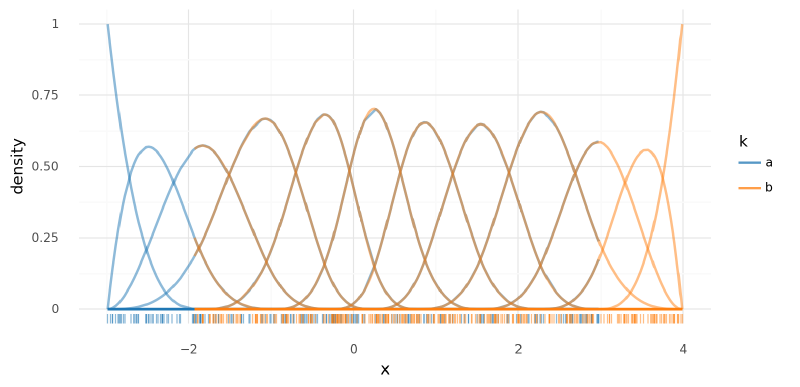
- The weights for each spline do not correspond to the same range of $x$ values, i.e. $w_1$ for group “a” does not correspond to the same region of $x$ that $w_1$ for group “b” does. Therefore, we cannot build a hierarchical level atop $\bf{w}$ that takes advantage of the spatial relationship of the parameters.
- Though $x$ extends beyond 3, as evidenced by data for group “b,” predictions in that region cannot be made for group “a” because it is beyond the spline’s reach. Out-of-distribution predictions are often fraught in modeling splines, but in this case, we could logically want to use our understanding of group “b” to inform predictions of “a” up to values of $x=4$.
These are both alleviated in the next model.
Two groups: single spline basis and per-group weights#
This model is the same as the previous, but used a single spline basis for all of the data. This solves the issues above by aligning the parameters $\mathbf{w}$ and extending the region of $x$ covered by both groups.
Spline bases#
For this model, I included the intercept in the spline basis. This formed the varying intercept for each group and thus I only added a single global intercept $a$ to the model.
df = two_spline_data.data.copy().reset_index(drop=True)
knots, joint_B = build_spline(df, intercept=True)
m3_data = ModelData(data=df, B=joint_B, knots=knots)plot_spline_basis(m3_data)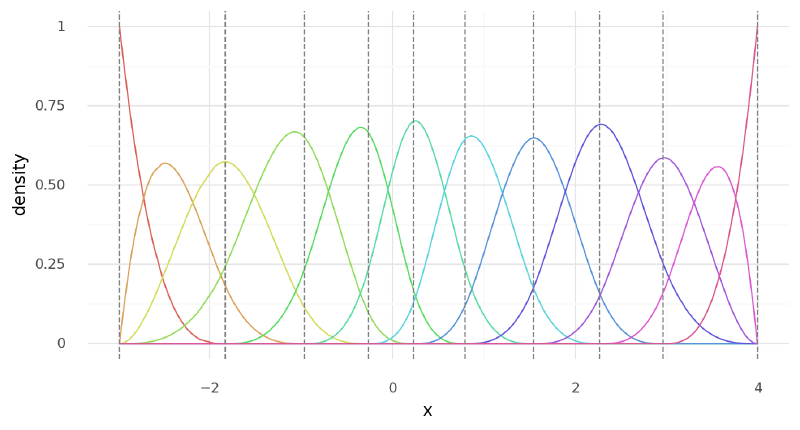
<ggplot: (339928863)>
basis_df = (
pd
.DataFrame(m3_data.B)
.assign(k=m3_data.data.k.values, x=m3_data.data.x.values)
.pivot_longer(["k", "x"], names_to="basis", values_to="density")
.assign(basis=lambda d: [f"{k}: {x}" for x, k in zip(d.basis, d.k)])
)
(
gg.ggplot(basis_df, gg.aes(x="x", color="k"))
+ gg.geom_line(gg.aes(group="basis", y="density"), alpha=0.5, size=1)
+ gg.geom_rug(data=m3_data.data, alpha=0.5, sides="b")
+ gg.scale_color_manual(values=group_pal)
)
<ggplot: (340750153)>
Model #3#
For this model, I followed the second option described previously where I included the intercept in the spline basis and then added a single, global intercept $a$ in the model. In this case, this pattern was required, otherwise there is weird behavior at the beginning of the spline for the group that has no data (group “b” in this case).
$$ \begin{aligned} y &\sim N(\mu, \sigma) \\ \mu &= a + \mathbf{B}_k \mathbf{w}_k^\text{T} \\ a &\sim N(0, 5) \\ w _ {i,k} &\sim N(0, 2) \quad \forall k \in K, \forall i \in {1, \dots, N} \end{aligned} $$
While MCMC does not sample from this model as easily as when using two different spline bases, it avoids the drawbacks mentioned for the previous model. Namely, we can make predictions for either group across the full observed range of $x$ (the range within the basis).
def build_model3(model_data: ModelData) -> pm.Model:
"""Model multiple curves with the same spline basis."""
B, df = np.asarray(model_data.B), model_data.data
B_dim = B.shape[1]
k = df.k.cat.codes.values.astype(int)
n_k = len(df.k.cat.categories)
with pm.Model(rng_seeder=RANDOM_SEED) as model:
a = pm.Normal("a", df.y.mean(), 5)
w = pm.Normal("w", 0, 2, shape=(B_dim, n_k))
_mu = []
for i in range(n_k):
_mu.append(at.dot(B[k == i, :], w[:, i]).reshape((-1, 1)))
mu = pm.Deterministic("mu", a + at.vertical_stack(*_mu).squeeze())
sigma = pm.Gamma("sigma", 2, 0.5)
y = pm.Normal("y", mu, sigma, observed=df.y.values)
return modelm3 = build_model3(m3_data)
pm.model_to_graphviz(m3)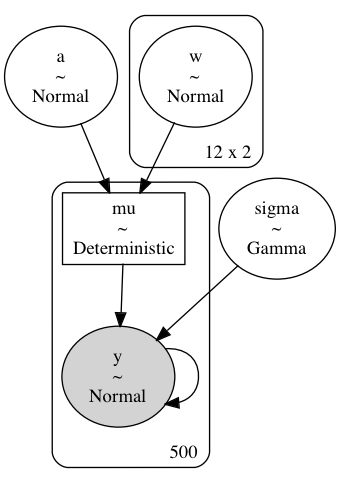
Sample from posterior#
with build_model3(m3_data):
m3_trace = pm.sample(**pm_sample_kwargs)
pm.sample_posterior_predictive(m3_trace, **pm_ppc_kwargs)Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (2 chains in 2 jobs)
NUTS: [a, w, sigma]
Sampling 2 chains for 500 tune and 500 draw iterations (1_000 + 1_000 draws total) took 127 seconds.
The chain reached the maximum tree depth. Increase max_treedepth, increase target_accept or reparameterize.
The chain reached the maximum tree depth. Increase max_treedepth, increase target_accept or reparameterize.
The estimated number of effective samples is smaller than 200 for some parameters.
Posterior analysis#
Note how the posterior distribution for the last and first value of $w$ for group “a” and “b,” respectively, are very wide (most easily seen in the forest plot below). This is because there is no data to inform these values and their posterior distribution is determined by their prior. Also, this increased uncertainty had ill-effects on the posterior sampling of the intercept $a$ because there is some non-identifiability between the first spline parameter of group “b” and $a$.
az.plot_trace(m3_trace, var_names=["~mu"])
plt.tight_layout()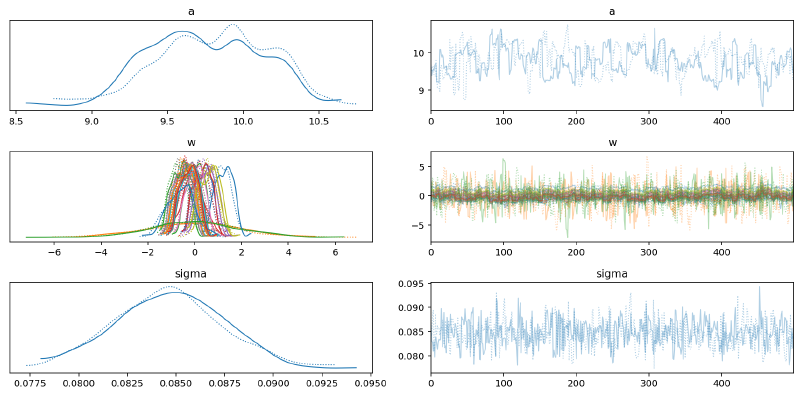
az.summary(m3_trace, var_names=["~mu"], hdi_prob=HDI_PROB)| mean | sd | hdi_5.5% | hdi_94.5% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| a | 9.776 | 0.374 | 9.233 | 10.344 | 0.038 | 0.027 | 100.0 | 187.0 | 1.01 |
| w[0, 0] | 0.307 | 0.375 | -0.260 | 0.867 | 0.037 | 0.026 | 104.0 | 189.0 | 1.01 |
| w[0, 1] | -0.062 | 2.077 | -4.015 | 2.783 | 0.080 | 0.078 | 666.0 | 431.0 | 1.00 |
| w[1, 0] | 0.018 | 0.378 | -0.557 | 0.569 | 0.038 | 0.027 | 100.0 | 188.0 | 1.01 |
| w[1, 1] | -0.113 | 0.486 | -0.904 | 0.649 | 0.038 | 0.027 | 167.0 | 348.0 | 1.01 |
| w[2, 0] | 0.560 | 0.375 | -0.021 | 1.113 | 0.038 | 0.027 | 101.0 | 196.0 | 1.01 |
| w[2, 1] | -0.325 | 0.388 | -0.930 | 0.256 | 0.037 | 0.027 | 107.0 | 284.0 | 1.01 |
| w[3, 0] | -0.497 | 0.378 | -1.122 | 0.015 | 0.037 | 0.026 | 104.0 | 206.0 | 1.01 |
| w[3, 1] | -0.284 | 0.375 | -0.850 | 0.277 | 0.038 | 0.027 | 101.0 | 153.0 | 1.01 |
| w[4, 0] | 0.685 | 0.373 | 0.118 | 1.236 | 0.037 | 0.026 | 103.0 | 179.0 | 1.01 |
| w[4, 1] | -0.437 | 0.375 | -1.031 | 0.091 | 0.038 | 0.027 | 98.0 | 186.0 | 1.01 |
| w[5, 0] | 1.231 | 0.380 | 0.633 | 1.767 | 0.038 | 0.027 | 100.0 | 201.0 | 1.01 |
| w[5, 1] | -0.463 | 0.375 | -1.056 | 0.060 | 0.038 | 0.027 | 99.0 | 165.0 | 1.01 |
| w[6, 0] | -0.674 | 0.372 | -1.249 | -0.128 | 0.038 | 0.027 | 98.0 | 170.0 | 1.01 |
| w[6, 1] | 0.324 | 0.375 | -0.260 | 0.850 | 0.038 | 0.027 | 101.0 | 190.0 | 1.01 |
| w[7, 0] | 0.427 | 0.381 | -0.194 | 0.960 | 0.038 | 0.027 | 102.0 | 192.0 | 1.01 |
| w[7, 1] | -0.191 | 0.375 | -0.777 | 0.349 | 0.037 | 0.026 | 103.0 | 203.0 | 1.01 |
| w[8, 0] | 0.010 | 0.374 | -0.623 | 0.515 | 0.038 | 0.027 | 94.0 | 160.0 | 1.01 |
| w[8, 1] | -0.560 | 0.375 | -1.136 | -0.018 | 0.037 | 0.027 | 102.0 | 188.0 | 1.01 |
| w[9, 0] | 0.557 | 0.401 | -0.071 | 1.150 | 0.037 | 0.026 | 122.0 | 189.0 | 1.01 |
| w[9, 1] | -0.211 | 0.377 | -0.815 | 0.310 | 0.037 | 0.027 | 100.0 | 195.0 | 1.01 |
| w[10, 0] | -0.606 | 0.575 | -1.578 | 0.223 | 0.038 | 0.027 | 232.0 | 484.0 | 1.00 |
| w[10, 1] | -0.333 | 0.379 | -0.915 | 0.229 | 0.038 | 0.027 | 103.0 | 194.0 | 1.01 |
| w[11, 0] | 0.057 | 1.915 | -2.874 | 3.228 | 0.075 | 0.073 | 664.0 | 606.0 | 1.00 |
| w[11, 1] | -0.255 | 0.374 | -0.838 | 0.277 | 0.038 | 0.027 | 99.0 | 205.0 | 1.01 |
| sigma | 0.085 | 0.003 | 0.080 | 0.089 | 0.000 | 0.000 | 662.0 | 631.0 | 1.00 |
The forest plot below highlights the variability of the spline parameters where they were not informed by data.
az.plot_forest(m3_trace, var_names=["w"], hdi_prob=HDI_PROB, combined=True)
plt.show()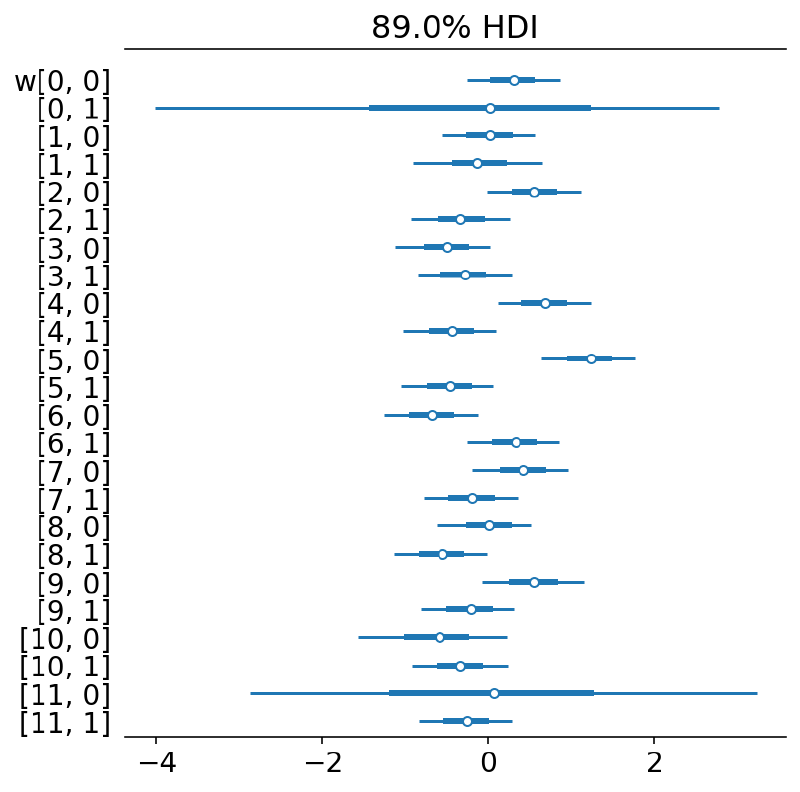
The fit of the model looked pretty good, but there were some notable differences between these results and those from using separate spline bases.
plot_posterior_mu(m3_trace, data=m3_data.data)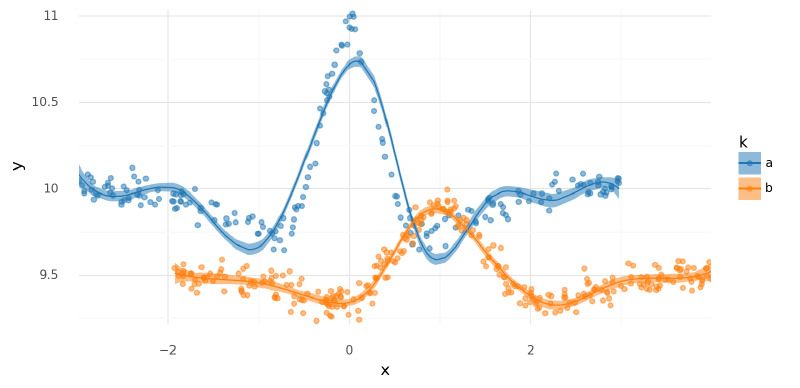
<ggplot: (341642237)>
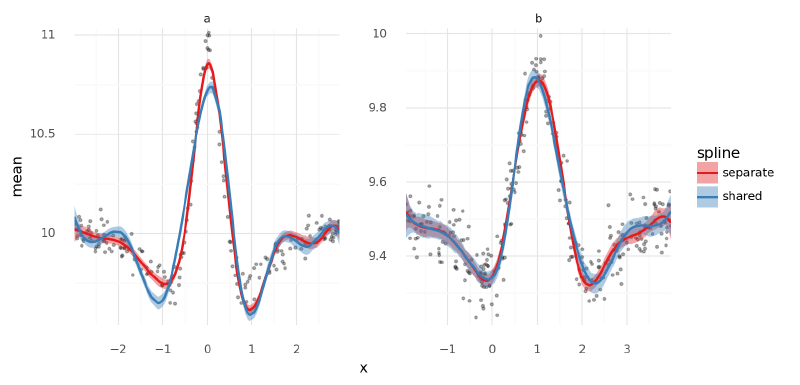
Below, I plotted the posteriors for $\mu$ for the models with separate and shared spline bases, separating the two groups into different panels. The largest difference is in the first dip around $x=-1$ for group “a” where the model with a separate spline basis for each group appears to have greater accuracy. This is likely caused by the placement of the knots for the basis being better positioned for group “a” in that case. This problem could likely be remedied by adding more knots.
compare_traces = {"separate": m2_trace, "shared": m3_trace}
compare_mu_df = pd.concat([
az
.summary(t, var_names="mu", hdi_prob=HDI_PROB, kind="stats")
.reset_index()
.assign(model=n)
.merge(m3_data.data, left_index=True, right_index=True)
for n, t in compare_traces.items()
])
(
gg.ggplot(compare_mu_df, gg.aes(x="x", y="mean"))
+ gg.facet_wrap("~k", nrow=1, scales="free")
+ gg.geom_point(gg.aes(y="y"), data=m3_data.data, size=0.7, alpha=0.3)
+ gg.geom_ribbon(gg.aes(ymin="hdi_5.5%", ymax="hdi_94.5%", fill="model"), alpha=0.4)
+ gg.geom_line(gg.aes(color="model"), size=1)
+ gg.scale_x_continuous(expand=(0, 0))
+ gg.scale_y_continuous(expand=(0, 0.02))
+ gg.scale_color_brewer(type="qual", palette="Set1")
+ gg.scale_fill_brewer(type="qual", palette="Set1")
+ gg.theme(subplots_adjust={"wspace": 0.25})
+ gg.labs(color="spline", fill="spline")
)/usr/local/Caskroom/miniconda/base/envs/speclet/lib/python3.9/site-packages/plotnine/utils.py:371: FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead.
/usr/local/Caskroom/miniconda/base/envs/speclet/lib/python3.9/site-packages/plotnine/utils.py:371: FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead.
/usr/local/Caskroom/miniconda/base/envs/speclet/lib/python3.9/site-packages/plotnine/utils.py:371: FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead.
<ggplot: (341671647)>
summarize_and_plot_ppc(m3_trace, m3_data.data)/var/folders/r4/qpcdgl_14hbd412snp1jnv300000gn/T/ipykernel_16319/1935723833.py:5: FutureWarning: hdi currently interprets 2d data as (draw, shape) but this will change in a future release to (chain, draw) for coherence with other functions
<ggplot: (341841412)>
Out-of-distribution predictions#
Unlike before, we could make predictions for each group across the full range of observed $x$ values because the spline basis covered the full area.
new_m3_data = build_new_data(m3_data)
new_data = new_m3_data.data.copy()
new_data = pd.concat([new_data.assign(k=k) for k in ["a", "b"]]).reset_index(drop=True)
new_data["k"] = pd.Categorical(new_data["k"], categories=["a", "b"], ordered=True)
new_m3_data.B = np.vstack([np.asarray(new_m3_data.B) for _ in range(2)])
new_m3_data.data = new_datawith build_model3(new_m3_data):
m3_post_pred_new = pm.sample_posterior_predictive(
trace=m3_trace,
var_names=["mu", "y"],
return_inferencedata=True,
extend_inferencedata=False,
progressbar=False,
)As expected, the predictive distributions for each group were very wide when the inputs exceed where there is data. Beyond where there is data, the posterior predictions were the same as the prior predictions because there was no data to inform the likelihood of Bayes rule. Note that if there was no global intercept $a$ included in the model, the out-of-distribution predictions would collapse to the prior on $\mathbf{w}$ which is centered at 0 causing massive drooping tails in the curves where there is no supporting data.
(
summarize_and_plot_ppc(m3_post_pred_new, new_m3_data.data, plot_pts=False)
+ gg.geom_point(gg.aes(x="x", y="y", color="k"), data=m3_data.data, size=0.1)
)/var/folders/r4/qpcdgl_14hbd412snp1jnv300000gn/T/ipykernel_16319/1935723833.py:5: FutureWarning: hdi currently interprets 2d data as (draw, shape) but this will change in a future release to (chain, draw) for coherence with other functions
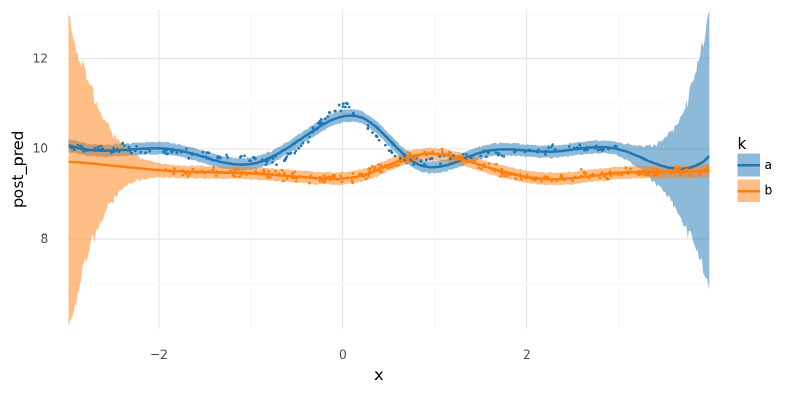
<ggplot: (341830226)>
Comments#
While not perfect and slower to sample, this model had several oft-desired features. In the next model, I added hierarchical priors to the spline to help with out-of-distribution predictions.
Two groups: per-group weights with hierarchical prior#
When we used two separate splines bases, one for each group, one annoyance was that the values for the spline weights $mathbf{w}$ in the model were not aligned. Therefore, knowledge about $w_{\text{a},1}$ was not necessarily informative about $w_{\text{b},1}$ because they were in reference to different ranges of $x$. Using the same spline basis for both groups (introduced in the previous model) aligns the weight parameters. With this in place, hierarchical priors can be included over the weight parameters to relate them to each other in the model. This was especially powerful in the current case because where group “a” had no data, the parameters for “a” could be informed by the parameters for “b,” and vice versa.
Model #4#
$$ \begin{aligned} y &\sim N(\mu, \sigma) \\ \mu_k &= a + \mathbf{B}_k \mathbf{w}_k^\text{T} \quad \forall k \in K \\ a &\sim N(0, 2.5) \\ w_k &\sim N(\mathbf{\mu} _ \mathbf{w}, \sigma _ \mathbf{w}) \quad \forall k \in K \\ \mu _ {w,i} &\sim N(0, 1) \quad \forall i \in {1, \dots, N} \\ \sigma _ \mathbf{w} &\sim \text{Gam}(2, 0.5) \end{aligned} $$
def build_model4(model_data: ModelData) -> pm.Model:
data, B = model_data.data, np.asarray(model_data.B)
B_dim = B.shape[1]
k = data.k.cat.codes.values.astype(int)
n_k = len(data.k.cat.categories)
with pm.Model(rng_seeder=RANDOM_SEED) as m4:
a = pm.Normal("a", data.y.mean(), 2.5)
mu_w = pm.Normal("mu_w", 0, 1, shape=(B_dim, 1))
sigma_w = pm.Gamma("sigma_w", 2, 0.5)
w = pm.Normal("w", mu_w, sigma_w, shape=(B_dim, n_k))
_mu = []
for i in range(n_k):
_mu.append(pm.math.dot(B[k == i], w[:, i]).reshape((-1, 1)))
mu = pm.Deterministic("mu", a + at.vertical_stack(*_mu).squeeze())
sigma = pm.Gamma("sigma", 2, 0.5)
y = pm.Normal("y", mu, sigma, observed=data.y.values)
return m4m4 = build_model4(m3_data)
pm.model_to_graphviz(m4)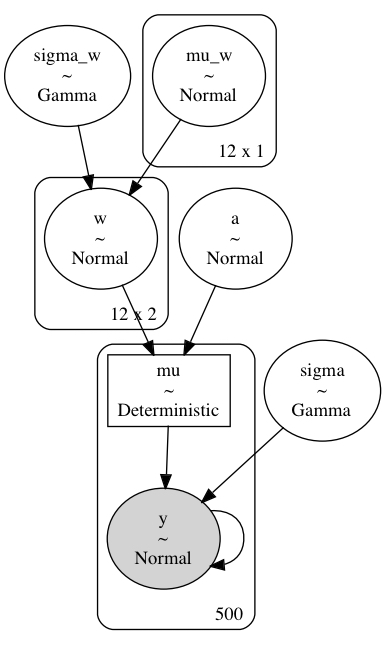
Sample from posterior#
m4_sample_kwargs = pm_sample_kwargs.copy()
m4_sample_kwargs["target_accept"] = 0.99
with build_model4(m3_data):
m4_trace = pm.sample(**m4_sample_kwargs)
pm.sample_posterior_predictive(m4_trace, **pm_ppc_kwargs)Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (2 chains in 2 jobs)
NUTS: [a, mu_w, sigma_w, w, sigma]
Sampling 2 chains for 500 tune and 500 draw iterations (1_000 + 1_000 draws total) took 180 seconds.
The estimated number of effective samples is smaller than 200 for some parameters.
Posterior analysis#
Again, MCMC has a bit of trouble, but it sampled sufficiently well for our purposes. Notice how the posterior distributions for the values of $\mathbf{w}$ outside of the observed data for each group are tighter than before. This is because the hierarchical model partially pooled data to inform these regions even without directly observing any data.
az.plot_trace(m4_trace, var_names=["~mu"])
plt.tight_layout()
plt.show()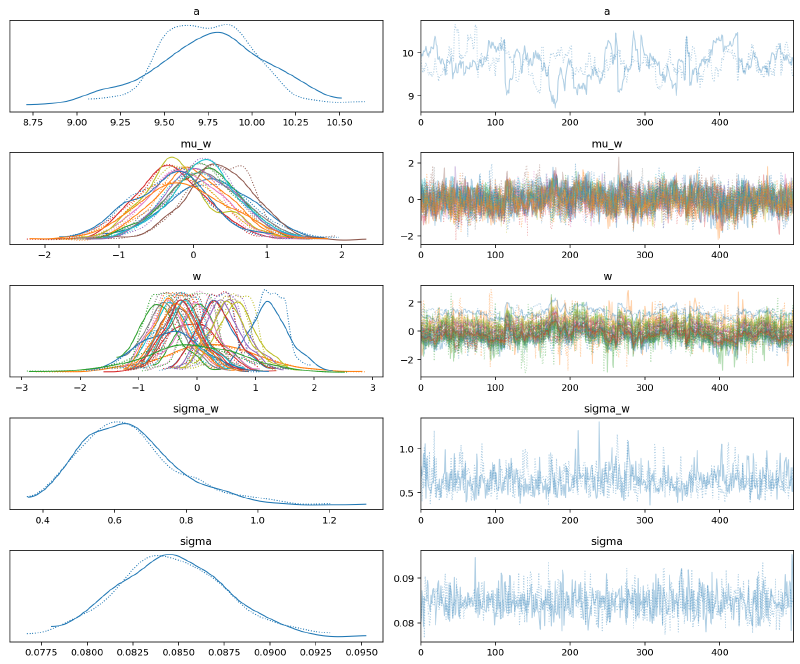
az.summary(m4_trace, var_names=["~mu"], hdi_prob=HDI_PROB)| mean | sd | hdi_5.5% | hdi_94.5% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| a | 9.755 | 0.309 | 9.283 | 10.286 | 0.037 | 0.026 | 70.0 | 141.0 | 1.01 |
| mu_w[0, 0] | 0.210 | 0.585 | -0.737 | 1.112 | 0.028 | 0.020 | 449.0 | 643.0 | 1.00 |
| mu_w[1, 0] | -0.015 | 0.494 | -0.801 | 0.770 | 0.026 | 0.019 | 357.0 | 550.0 | 1.00 |
| mu_w[2, 0] | 0.103 | 0.498 | -0.661 | 0.925 | 0.033 | 0.023 | 229.0 | 426.0 | 1.00 |
| mu_w[3, 0] | -0.302 | 0.503 | -1.049 | 0.551 | 0.029 | 0.020 | 304.0 | 541.0 | 1.00 |
| mu_w[4, 0] | 0.132 | 0.468 | -0.696 | 0.806 | 0.034 | 0.024 | 195.0 | 431.0 | 1.01 |
| mu_w[5, 0] | 0.356 | 0.476 | -0.373 | 1.093 | 0.030 | 0.021 | 245.0 | 599.0 | 1.00 |
| mu_w[6, 0] | -0.122 | 0.483 | -0.888 | 0.599 | 0.028 | 0.020 | 294.0 | 590.0 | 1.00 |
| mu_w[7, 0] | 0.116 | 0.506 | -0.708 | 0.885 | 0.036 | 0.025 | 205.0 | 353.0 | 1.01 |
| mu_w[8, 0] | -0.189 | 0.484 | -0.914 | 0.624 | 0.034 | 0.024 | 202.0 | 530.0 | 1.01 |
| mu_w[9, 0] | 0.148 | 0.480 | -0.616 | 0.918 | 0.032 | 0.023 | 221.0 | 533.0 | 1.01 |
| mu_w[10, 0] | -0.326 | 0.533 | -1.228 | 0.447 | 0.030 | 0.021 | 322.0 | 663.0 | 1.00 |
| mu_w[11, 0] | -0.163 | 0.590 | -1.051 | 0.817 | 0.040 | 0.028 | 218.0 | 495.0 | 1.01 |
| w[0, 0] | 0.328 | 0.310 | -0.183 | 0.818 | 0.037 | 0.026 | 71.0 | 133.0 | 1.01 |
| w[0, 1] | 0.219 | 0.877 | -1.349 | 1.465 | 0.038 | 0.029 | 527.0 | 562.0 | 1.00 |
| w[1, 0] | 0.041 | 0.313 | -0.479 | 0.545 | 0.037 | 0.026 | 74.0 | 129.0 | 1.01 |
| w[1, 1] | -0.094 | 0.416 | -0.701 | 0.598 | 0.036 | 0.026 | 131.0 | 414.0 | 1.01 |
| w[2, 0] | 0.576 | 0.314 | 0.075 | 1.079 | 0.038 | 0.027 | 70.0 | 137.0 | 1.02 |
| w[2, 1] | -0.304 | 0.327 | -0.862 | 0.185 | 0.038 | 0.027 | 74.0 | 159.0 | 1.01 |
| w[3, 0] | -0.474 | 0.311 | -0.997 | 0.009 | 0.037 | 0.026 | 72.0 | 132.0 | 1.01 |
| w[3, 1] | -0.264 | 0.311 | -0.778 | 0.224 | 0.037 | 0.026 | 72.0 | 131.0 | 1.01 |
| w[4, 0] | 0.707 | 0.311 | 0.208 | 1.213 | 0.038 | 0.027 | 70.0 | 124.0 | 1.02 |
| w[4, 1] | -0.416 | 0.312 | -0.980 | 0.033 | 0.037 | 0.027 | 70.0 | 140.0 | 1.02 |
| w[5, 0] | 1.246 | 0.313 | 0.672 | 1.684 | 0.037 | 0.026 | 73.0 | 140.0 | 1.01 |
| w[5, 1] | -0.440 | 0.311 | -1.007 | -0.002 | 0.037 | 0.026 | 70.0 | 140.0 | 1.01 |
| w[6, 0] | -0.646 | 0.311 | -1.166 | -0.145 | 0.037 | 0.026 | 71.0 | 148.0 | 1.01 |
| w[6, 1] | 0.341 | 0.310 | -0.212 | 0.802 | 0.037 | 0.026 | 71.0 | 138.0 | 1.01 |
| w[7, 0] | 0.438 | 0.313 | -0.093 | 0.924 | 0.038 | 0.027 | 70.0 | 134.0 | 1.01 |
| w[7, 1] | -0.166 | 0.312 | -0.688 | 0.311 | 0.038 | 0.027 | 70.0 | 133.0 | 1.01 |
| w[8, 0] | 0.041 | 0.314 | -0.425 | 0.596 | 0.037 | 0.026 | 73.0 | 126.0 | 1.01 |
| w[8, 1] | -0.541 | 0.311 | -1.109 | -0.095 | 0.037 | 0.026 | 72.0 | 128.0 | 1.01 |
| w[9, 0] | 0.551 | 0.325 | -0.020 | 1.019 | 0.037 | 0.026 | 78.0 | 142.0 | 1.01 |
| w[9, 1] | -0.190 | 0.310 | -0.699 | 0.302 | 0.037 | 0.026 | 71.0 | 136.0 | 1.01 |
| w[10, 0] | -0.484 | 0.523 | -1.370 | 0.285 | 0.038 | 0.027 | 190.0 | 340.0 | 1.01 |
| w[10, 1] | -0.315 | 0.313 | -0.796 | 0.219 | 0.038 | 0.027 | 71.0 | 134.0 | 1.01 |
| w[11, 0] | -0.138 | 0.865 | -1.506 | 1.259 | 0.042 | 0.032 | 422.0 | 449.0 | 1.01 |
| w[11, 1] | -0.234 | 0.310 | -0.811 | 0.207 | 0.037 | 0.026 | 71.0 | 134.0 | 1.01 |
| sigma_w | 0.644 | 0.139 | 0.432 | 0.850 | 0.006 | 0.004 | 588.0 | 586.0 | 1.00 |
| sigma | 0.085 | 0.003 | 0.080 | 0.089 | 0.000 | 0.000 | 1192.0 | 789.0 | 1.00 |
az.plot_forest(m4_trace, var_names=["mu_w"], hdi_prob=HDI_PROB, combined=True)
plt.show()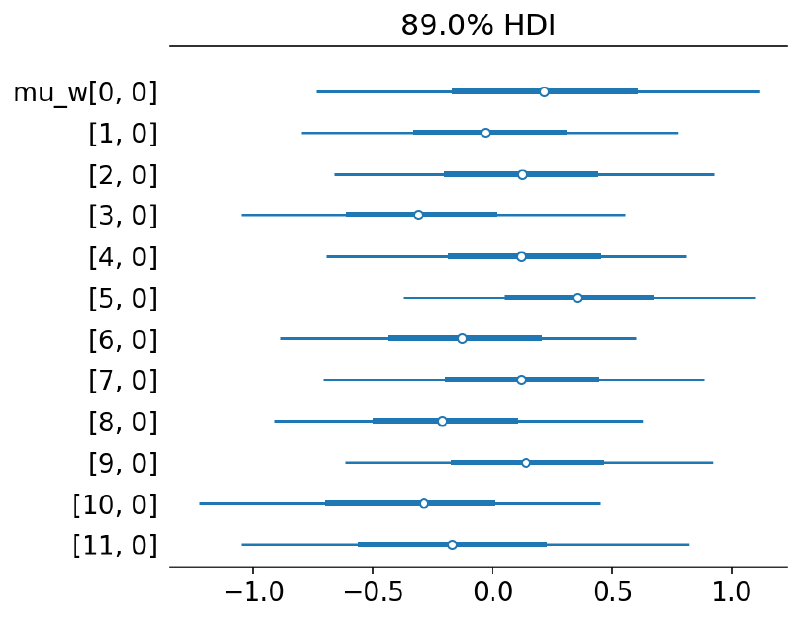
az.plot_forest(
[m3_trace, m4_trace],
model_names=["m3: separate", "m4: hierarchical"],
var_names=["w"],
hdi_prob=HDI_PROB,
combined=True,
)
plt.show()
Again, the model visually performed very well.
plot_posterior_mu(m4_trace, m3_data.data)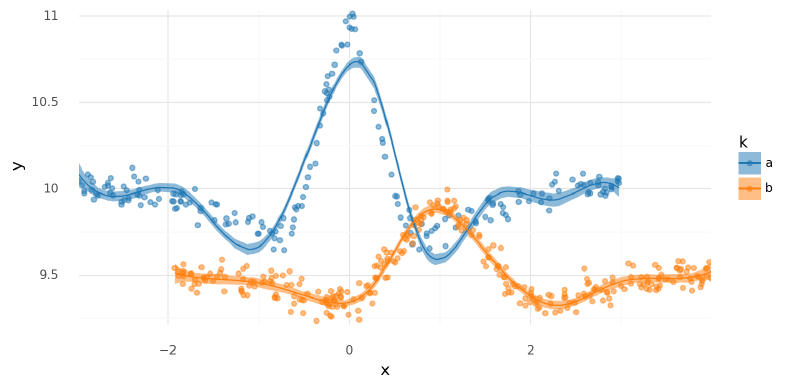
<ggplot: (341670650)>
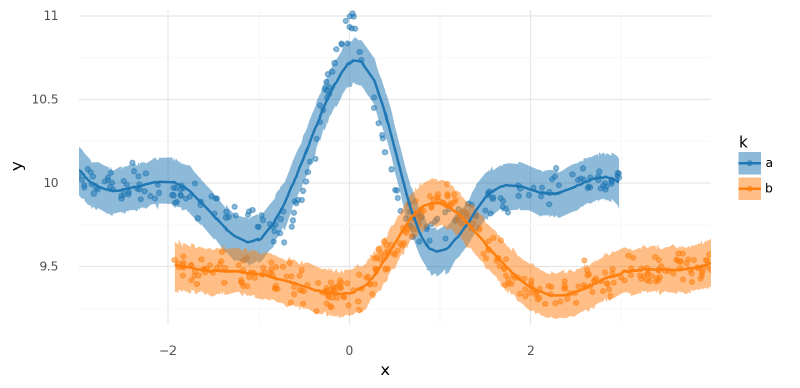
summarize_and_plot_ppc(m4_trace, m3_data.data)/var/folders/r4/qpcdgl_14hbd412snp1jnv300000gn/T/ipykernel_16319/1935723833.py:5: FutureWarning: hdi currently interprets 2d data as (draw, shape) but this will change in a future release to (chain, draw) for coherence with other functions
<ggplot: (341782020)>
Out-of-distribution predictions#
As mentioned previously, adding hierarchical priors to $\mathbf{w}$ helped tighten out-of-distribution predictions. Below, I plotted the posterior predictions of this model, followed by a comparison with the previous, non-hierarchical version. Note how when not informed by observed data, the predictions for one group tended towards the predictions of the other but still remain relatively uncertain. This was due to the sharing of information induced by the hierarchical prior distribution.
with build_model4(new_m3_data):
m4_post_pred_new = pm.sample_posterior_predictive(
trace=m4_trace,
var_names=["mu", "y"],
return_inferencedata=True,
extend_inferencedata=False,
)(
summarize_and_plot_ppc(m4_post_pred_new, new_m3_data.data, plot_pts=False)
+ gg.geom_point(gg.aes(x="x", y="y", color="k"), data=m3_data.data, size=0.1)
)/var/folders/r4/qpcdgl_14hbd412snp1jnv300000gn/T/ipykernel_16319/1935723833.py:5: FutureWarning: hdi currently interprets 2d data as (draw, shape) but this will change in a future release to (chain, draw) for coherence with other functions
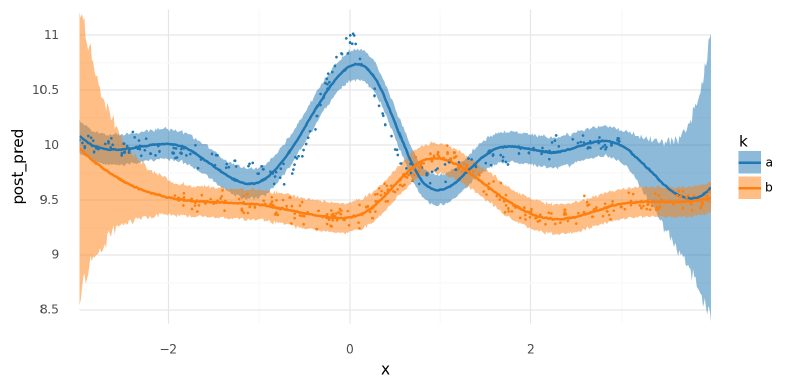
<ggplot: (341692145)>
comarisons = {"no pooling": m3_post_pred_new, "hierarchical": m4_post_pred_new}
compare_ppc_df = pd.concat([
summarize_ppc(t, new_m3_data.data).assign(model=n) for n, t in comarisons.items()
])
(
gg.ggplot(compare_ppc_df, gg.aes(x="x", y="post_pred"))
+ gg.facet_wrap("~k", nrow=1, scales="free")
+ gg.geom_ribbon(gg.aes(ymin="hdi_low", ymax="hdi_high", fill="model"), alpha=0.2)
+ gg.geom_line(gg.aes(color="model"), size=1)
+ gg.scale_x_continuous(expand=(0, 0))
+ gg.scale_y_continuous(expand=(0, 0.02))
+ gg.scale_color_brewer(type="qual", palette="Set1")
+ gg.scale_fill_brewer(type="qual", palette="Set1")
+ gg.theme(subplots_adjust={"wspace": 0.25})
+ gg.labs(color="spline", fill="spline")
)/var/folders/r4/qpcdgl_14hbd412snp1jnv300000gn/T/ipykernel_16319/1935723833.py:5: FutureWarning: hdi currently interprets 2d data as (draw, shape) but this will change in a future release to (chain, draw) for coherence with other functions
/var/folders/r4/qpcdgl_14hbd412snp1jnv300000gn/T/ipykernel_16319/1935723833.py:5: FutureWarning: hdi currently interprets 2d data as (draw, shape) but this will change in a future release to (chain, draw) for coherence with other functions
/usr/local/Caskroom/miniconda/base/envs/speclet/lib/python3.9/site-packages/plotnine/utils.py:371: FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead.
/usr/local/Caskroom/miniconda/base/envs/speclet/lib/python3.9/site-packages/plotnine/utils.py:371: FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead.
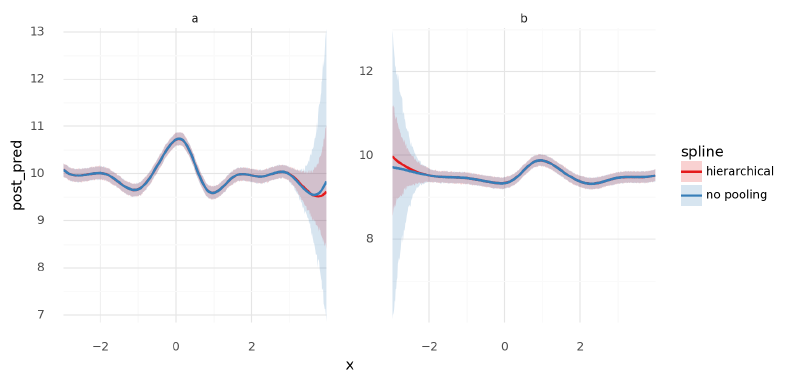
<ggplot: (342201567)>
Comments#
This model performed great and it would definitely be possible to stop here.
Note that the choice of partial pooling is one made by the modeler and may not necessarily always be the best choice. The model’s structure is a form of a priori knowledge, thus choice of hierarchical distributions should reflect prior knowledge about the system being modeled.
One group: multivariate-normal prior on weights#
There is another change we could make to the hierarchical model above to further replace the spline parameters. A naive approach could be to add a single prior distribution on the hyper-prior for $\mathbf{w}$: $\mathbf{\mu}_\mathbf{w} \sim N(A,B)$, but we would be leaving out some information. This hyper-prior would be implicitly modeling that all of the spline parameters are equally related to each other, but we may believe that there could be spatial relationships such as neighboring parameters (e.g. $w_1$ and $w_2$) are possibly correlated. We can include this information by modeling $\mathbf{w}$ as a multivariate normal distribution.
Below, I build two models for a single curve to ease into this new addition. The first “Model #5 simple” is just a regular spline for a single curve like the first model, followed by “Model 5 multivariate normal” where I added the multivariate normal prior on $\mathbf{w}$, again for a single curve. Extending this to multiple curves was done in the next section.
Model #5 simple#
Again, I regressed a bit to start simple. Recall that the spline does not include an intercept so I added $a$ to the model.
def build_model5_simple(model_data: ModelData) -> pm.Model:
data, B = model_data.data, np.asarray(model_data.B)
B_dim = B.shape[1]
with pm.Model(rng_seeder=RANDOM_SEED) as m5:
sigma_w = pm.Gamma("sigma_w", 2, 0.5)
a = pm.Normal("a", data.y.mean(), 5)
w = pm.Normal("w", 0, sigma_w, shape=B_dim)
mu = pm.Deterministic("mu", a + pmmath.dot(B, w))
sigma = pm.Gamma("sigma", 2, 0.5)
y = pm.Normal("y", mu, sigma, observed=data.y.values)
return m5pm.model_to_graphviz(build_model5_simple(single_curve_data))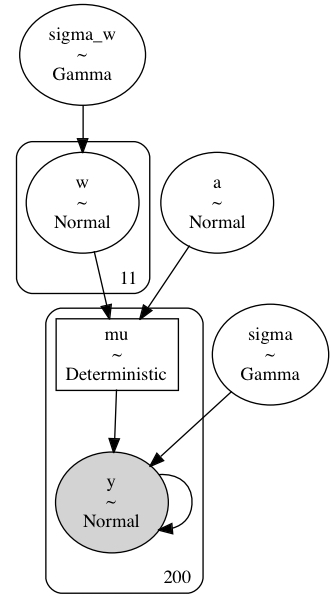
Sample from posterior#
with build_model5_simple(single_curve_data):
m5_s_trace = pm.sample(**pm_sample_kwargs)
pm.sample_posterior_predictive(m5_s_trace, **pm_ppc_kwargs)Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (2 chains in 2 jobs)
NUTS: [sigma_w, a, w, sigma]
Sampling 2 chains for 500 tune and 500 draw iterations (1_000 + 1_000 draws total) took 27 seconds.
The estimated number of effective samples is smaller than 200 for some parameters.
Model #5 multivariate normal#
Now I have replaced the normal prior with a multivariate normal prior on $\mathbf{w}$. I won’t go into detail here about how this was done but instead provide some references below. The main difference is now a covariance matrix can be learned for $\mathbf{w}$ that will describe how the parameters are correlated.
As mentioned in the resources below, if using the LKJCholeskyCov() prior for a non-observed variable, it is often best to use the non-centered parameterization.
Below, I included the code for a model with the standard parameterization, but I actually sample from the non-centered model here.
References for using the LKJ Cholesky prior in PyMC:
- The documentation for the
LKJCholeskyCov()function provides a great starting point: PyMC doc:LKJCholeskyCov - PyMC3 Example: “LKJ Cholesky Covariance Priors for Multivariate Normal Models”
- The classic prior on multilevel modeling uses the LKJ Cholskey in later models and shows how to go from the standard to non-centered parameterization: A Primer on Bayesian Methods for Multilevel Modeling
def build_model5_mv(model_data: ModelData) -> pm.Model:
data, B = model_data.data, np.asarray(model_data.B)
B_dim = B.shape[1]
with pm.Model(rng_seeder=RANDOM_SEED) as m5_mv:
_sd_dist = pm.Gamma.dist(2, 0.5, shape=B_dim)
chol, corr, stds = pm.LKJCholeskyCov(
"chol", eta=2, n=B_dim, sd_dist=_sd_dist, compute_corr=True
)
cov = pm.Deterministic("cov", chol.dot(chol.T))
w = pm.MvNormal("w", mu=0, chol=chol, shape=B_dim)
a = pm.Normal("a", data.y.mean(), 5)
mu = pm.Deterministic("mu", a + pm.math.dot(B, w))
sigma = pm.Gamma("sigma", 2, 0.5)
y = pm.Normal("y", mu, sigma, observed=data.y)
return m5_mvpm.model_to_graphviz(build_model5_mv(single_curve_data))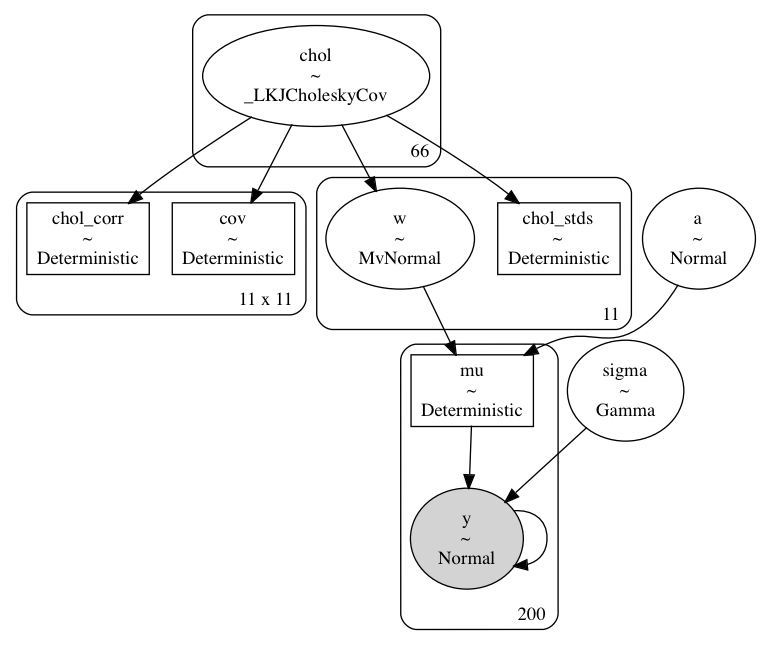
def build_model5_mv_noncentered(model_data: ModelData, lkj_eta: int = 2) -> pm.Model:
data, B = model_data.data, np.asarray(model_data.B)
B_dim = B.shape[1]
with pm.Model(rng_seeder=RANDOM_SEED) as m5_mv:
_sd_dist = pm.Gamma.dist(2, 0.5, shape=B_dim)
chol, corr, stds = pm.LKJCholeskyCov(
"chol", eta=lkj_eta, n=B_dim, sd_dist=_sd_dist, compute_corr=True
)
cov = pm.Deterministic("cov", chol.dot(chol.T))
delta_w = pm.Normal("delta_w", 0, 1, shape=B_dim)
w = pm.Deterministic("w", at.dot(chol, delta_w.T).T)
a = pm.Normal("a", data.y.mean(), 5)
mu = pm.Deterministic("mu", a + pm.math.dot(B, w))
sigma = pm.Gamma("sigma", 2, 0.5)
y = pm.Normal("y", mu, sigma, observed=data.y)
return m5_mvpm.model_to_graphviz(build_model5_mv_noncentered(single_curve_data))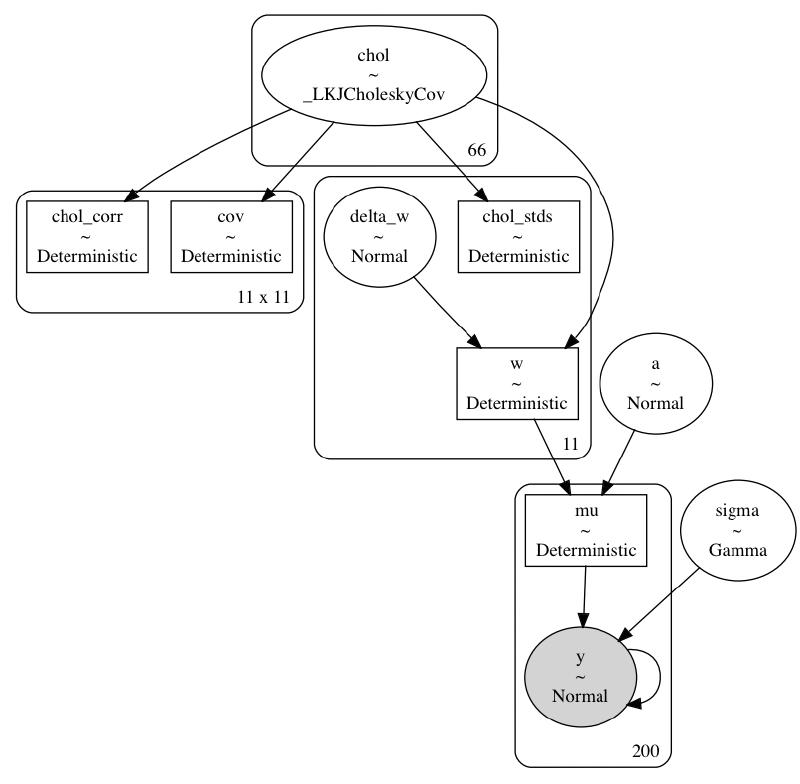
Sample from posterior#
m5_sample_kwargs = pm_sample_kwargs.copy()
m5_sample_kwargs["target_accept"] = 0.99
with build_model5_mv_noncentered(single_curve_data):
m5_mv_trace = pm.sample(**m5_sample_kwargs)
pm.sample_posterior_predictive(m5_mv_trace, **pm_ppc_kwargs)Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (2 chains in 2 jobs)
NUTS: [chol, delta_w, a, sigma]
Sampling 2 chains for 500 tune and 500 draw iterations (1_000 + 1_000 draws total) took 318 seconds.
The chain reached the maximum tree depth. Increase max_treedepth, increase target_accept or reparameterize.
The chain reached the maximum tree depth. Increase max_treedepth, increase target_accept or reparameterize.
The rhat statistic is larger than 1.05 for some parameters. This indicates slight problems during sampling.
The estimated number of effective samples is smaller than 200 for some parameters.
Posterior analysis#
This model had some difficulty fitting and could probably benefit from further experimentation. For demonstrative purposes, though, it should suffice.
az.plot_trace(m5_s_trace, var_names=["~mu"])
plt.tight_layout()
plt.show()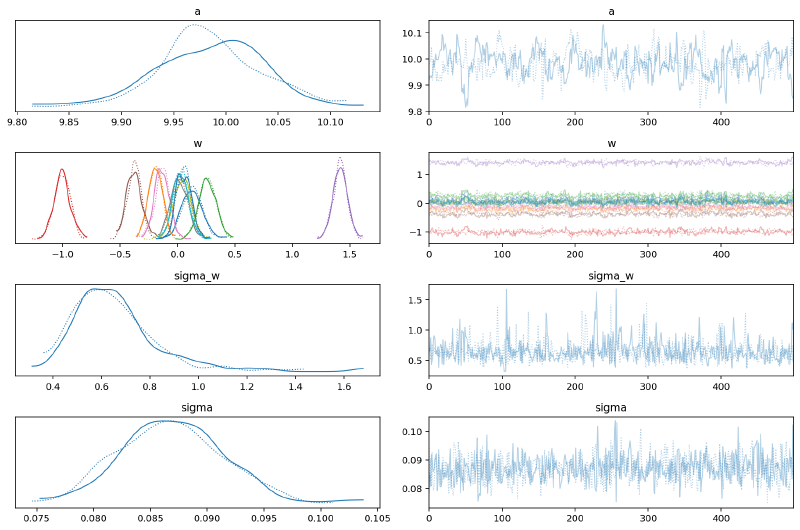
az.plot_trace(m5_mv_trace, var_names=["a", "w", "sigma", "chol", "chol_stds"])
plt.tight_layout()
plt.show()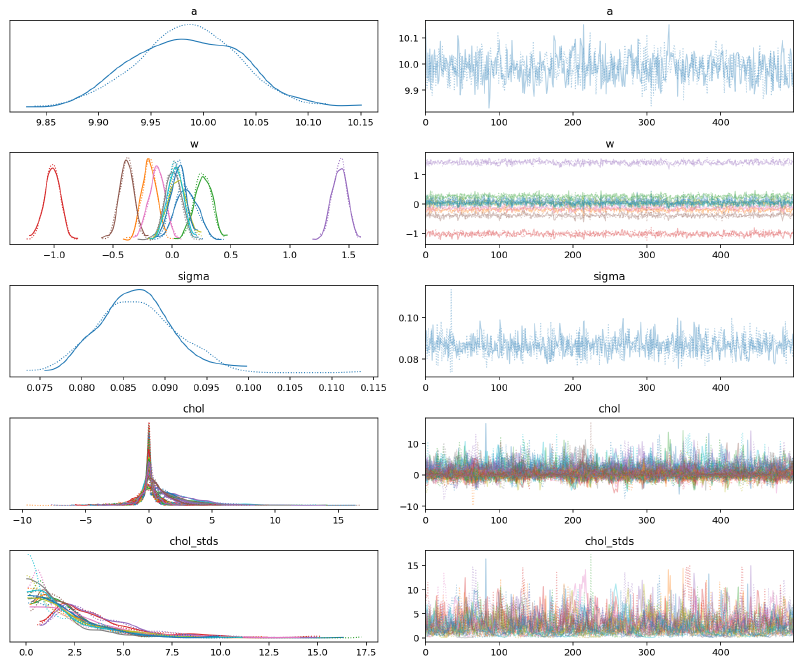
Note how the estimates for $\mathbf{w}$ did not change substantially.
az.plot_forest(
[m5_s_trace, m5_mv_trace],
model_names=["simple", "MV"],
var_names="w",
hdi_prob=HDI_PROB,
combined=True,
)
plt.show()
Also, the posterior distribution for $\mu$ did not change significantly with the addition of the multivariate normal prior.
plot_posterior_mu(m5_s_trace, data=single_curve_data.data)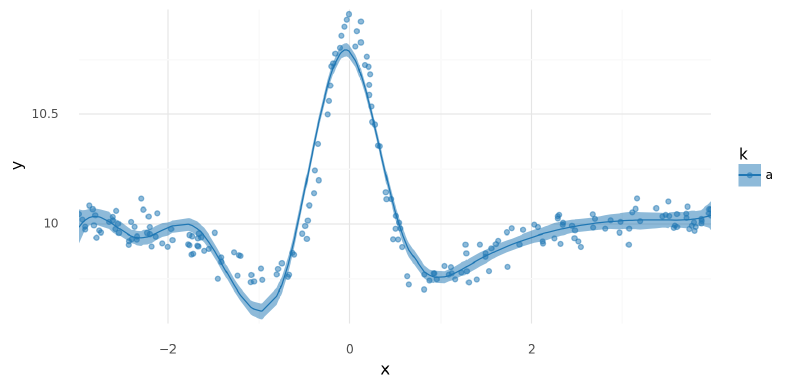
<ggplot: (342508090)>
plot_posterior_mu(m5_mv_trace, data=single_curve_data.data)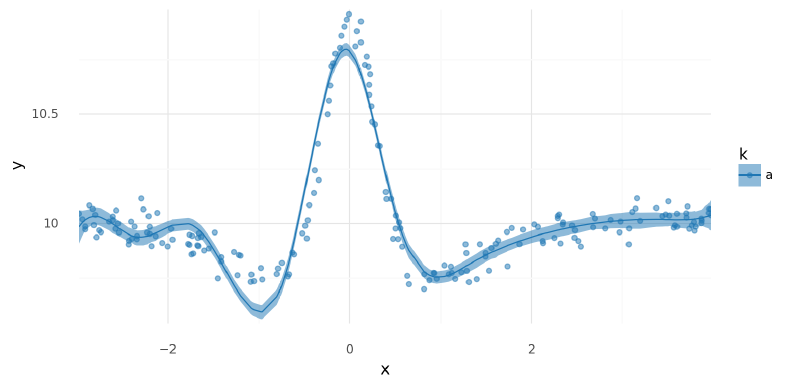
<ggplot: (343035895)>
The following plot shows the mean of the posterior estimates for correlations between values of $\mathbf{w}$. They were fairly weak, but you can see that some of the strongest measurements were negative correlations between positions 3, 4, and 5 where the main peaks were located in the data.
def plot_chol_corr(trace: az.InferenceData) -> gg.ggplot:
corr_post_df = (
az
.summary(trace, var_names=["chol_corr"], hdi_prob=HDI_PROB)
.reset_index(drop=False)
.rename(columns={"index": "parameter"})
.assign(_idx=lambda d: [list(re.findall("[0-9]+", x)) for x in d.parameter])
.assign(
d0=lambda d: [int(x[0]) for x in d["_idx"]],
d1=lambda d: [int(x[1]) for x in d["_idx"]],
)
)
corr_post_df.loc[corr_post_df["d0"] == corr_post_df["d1"], "mean"] = np.nan
return (
gg.ggplot(corr_post_df, gg.aes(x="d0", y="d1"))
+ gg.geom_tile(gg.aes(fill="mean"))
+ gg.scale_x_continuous(expand=(0, 0), breaks=np.arange(0, 100))
+ gg.scale_y_continuous(expand=(0, 0), breaks=np.arange(0, 100))
+ gg.scale_fill_gradient2(
low="blue", mid="white", high="red", na_value="lightgray"
)
+ gg.coord_fixed()
+ gg.theme(figure_size=(4, 4))
+ gg.labs(x="w", y="w", fill="corr.")
)plot_chol_corr(m5_mv_trace)/usr/local/Caskroom/miniconda/base/envs/speclet/lib/python3.9/site-packages/arviz/stats/diagnostics.py:561: RuntimeWarning: invalid value encountered in double_scalars
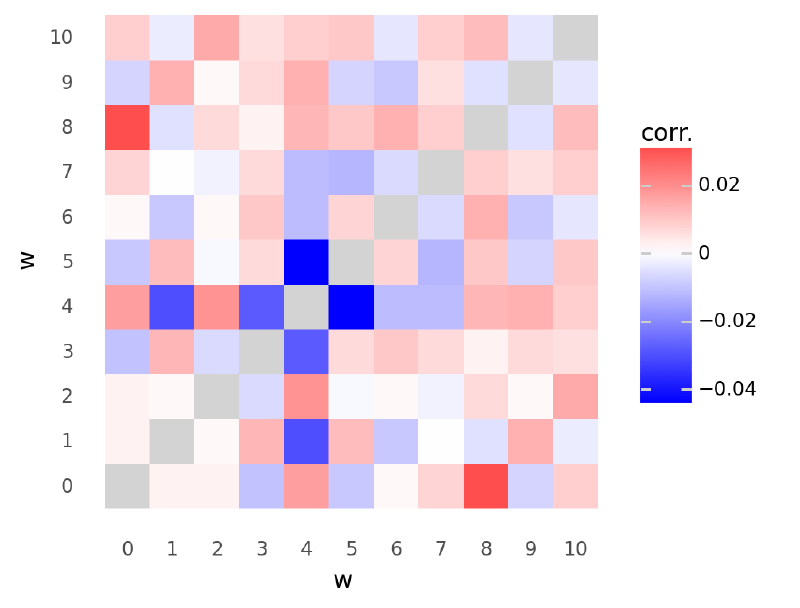
<ggplot: (341381190)>
az.plot_parallel(m5_mv_trace, var_names="w")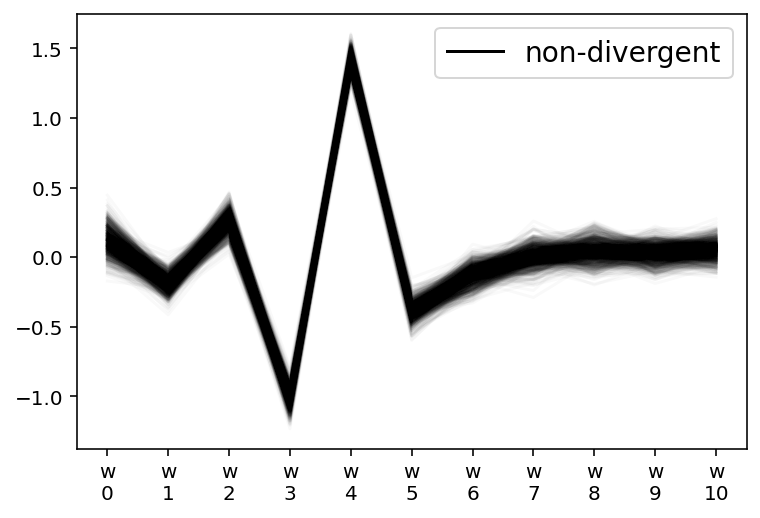
az.plot_forest(m5_mv_trace, var_names=["chol_corr"], hdi_prob=HDI_PROB, combined=True)
plt.show()
The following plot shows the posterior distributions for the correlation of neighboring parameters $w_{i, i+1}$. Relative to the width of the 89% HDI, the differences were small, but the expected trends were identified by the model.
chol_corr_post = (
az
.summary(m5_mv_trace, var_names="chol_corr", kind="stats", hdi_prob=HDI_PROB)
.reset_index(drop=False)
.assign(_idx=lambda d: [re.findall("[0-9]+", x) for x in d["index"]])
.assign(
corr0=lambda d: [int(x[0]) for x in d["_idx"]],
corr1=lambda d: [int(x[1]) for x in d["_idx"]],
)
.query("corr0 == (corr1-1)")
.reset_index(drop=True)
.assign(
correlation=lambda d: [f"$w_{a}$:$w_{b}$" for a, b in zip(d.corr0, d.corr1)]
)
)
(
gg.ggplot(chol_corr_post, gg.aes(x="correlation", y="mean"))
+ gg.geom_linerange(gg.aes(ymin="hdi_5.5%", ymax="hdi_94.5%"))
+ gg.geom_point()
+ gg.theme(figure_size=(6, 3))
+ gg.labs(x="comparison", y="correlation (mean ± 89% HDI)")
)
<ggplot: (340443570)>
Comments#
Introducing the multivariate distribution made it more difficult for MCMC to sample from the posterior of the model, but it did capture some interesting effects. Below this strategy was extended to multiple curves.
Two group: multivariate normal prior on weights#
The last model I built here extended the multivariate normal distribution on $\mathbf{w}$ to the multi-curve model.
Again, I used the non-centered parameterization.
The commented out line in the function build_model6() shows how the multivariate distribution would be constructed in the standard (centered) parameterization.
Model #6#
def build_model6(model_data: ModelData) -> pm.Model:
"""Multi-curve spline regression with a multivariate normal prior."""
data, B = model_data.data, np.asarray(model_data.B)
B_dim = B.shape[1]
k = data.k.cat.codes.values.astype(int)
n_k = len(data.k.cat.categories)
with pm.Model(rng_seeder=RANDOM_SEED) as model:
_sd_dist = pm.Gamma.dist(2, 0.5, shape=B_dim)
chol, corr, stds = pm.LKJCholeskyCov(
"chol", eta=2, n=B_dim, sd_dist=_sd_dist, compute_corr=True
)
cov = pm.Deterministic("cov", chol.dot(chol.T))
mu_w = pm.Normal("mu_w", 0, 1, shape=(B_dim, 1))
delta_w = pm.Normal("delta_w", 0, 1, shape=(B_dim, n_k))
w = pm.Deterministic("w", mu_w + at.dot(chol, delta_w))
# w = pm.MvNormal("w", mu=mu_w, chol=chol, shape=(B_dim, n_k))
_mu = []
for i in range(n_k):
_mu.append(pm.math.dot(B[k == i, :], w[:, i]).reshape((-1, 1)))
a = pm.Normal("a", data.y.mean(), 2.5)
mu = pm.Deterministic("mu", a + at.vertical_stack(*_mu).squeeze())
sigma = pm.Gamma("sigma", 2, 0.5)
y = pm.Normal("y", mu, sigma, observed=data.y.values)
return modelpm.model_to_graphviz(build_model6(m3_data))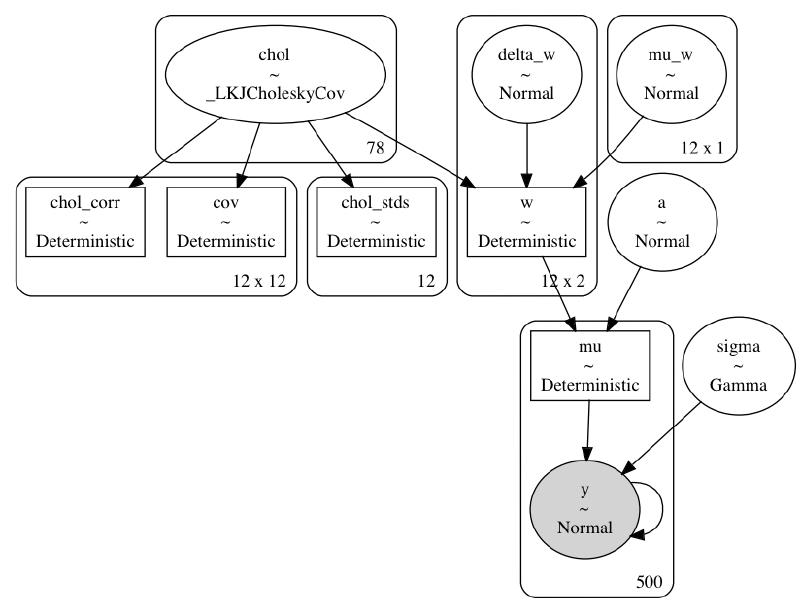
Sample from posterior#
m6_sample_kwargs = pm_sample_kwargs.copy()
m6_sample_kwargs["target_accept"] = 0.99
with build_model6(m3_data):
m6_trace = pm.sample(**m6_sample_kwargs)
pm.sample_posterior_predictive(m6_trace, **pm_ppc_kwargs)Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (2 chains in 2 jobs)
NUTS: [chol, mu_w, delta_w, a, sigma]
Sampling 2 chains for 500 tune and 500 draw iterations (1_000 + 1_000 draws total) took 454 seconds.
The chain reached the maximum tree depth. Increase max_treedepth, increase target_accept or reparameterize.
The chain reached the maximum tree depth. Increase max_treedepth, increase target_accept or reparameterize.
The rhat statistic is larger than 1.05 for some parameters. This indicates slight problems during sampling.
The estimated number of effective samples is smaller than 200 for some parameters.
Posterior analysis#
MCMC again struggled to fit this model, but the results are worth investigating.
az.plot_trace(
m6_trace,
var_names=["a", "w", "delta_w", "chol_stds"],
)
plt.tight_layout()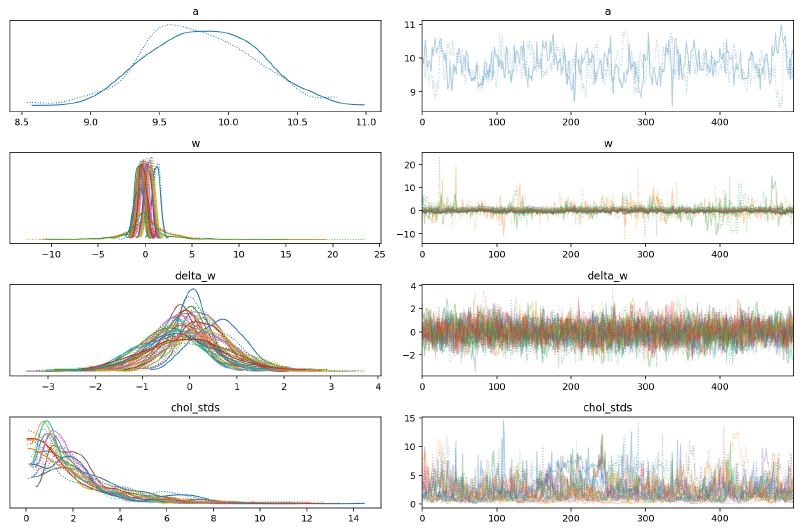
We can see again that the posterior distributions for values of $\mathbf{w}$ with no data were far wider than those with data, but these posteriors are much wider than in the hierarchical model. I believe this discrepancy was caused by how in the hierarchical model there was a single standard deviation parameter for $w$ but there was a separate distribution for each spline parameter $w_{i,:}$ with the multivariate normal prior.
az.plot_forest(
[m4_trace, m6_trace],
model_names=["hierarchical", "MV"],
var_names=["a", "w"],
hdi_prob=HDI_PROB,
combined=True,
)
plt.show()
az.plot_forest(m6_trace, var_names="chol_corr", hdi_prob=HDI_PROB, combined=True)
plt.show()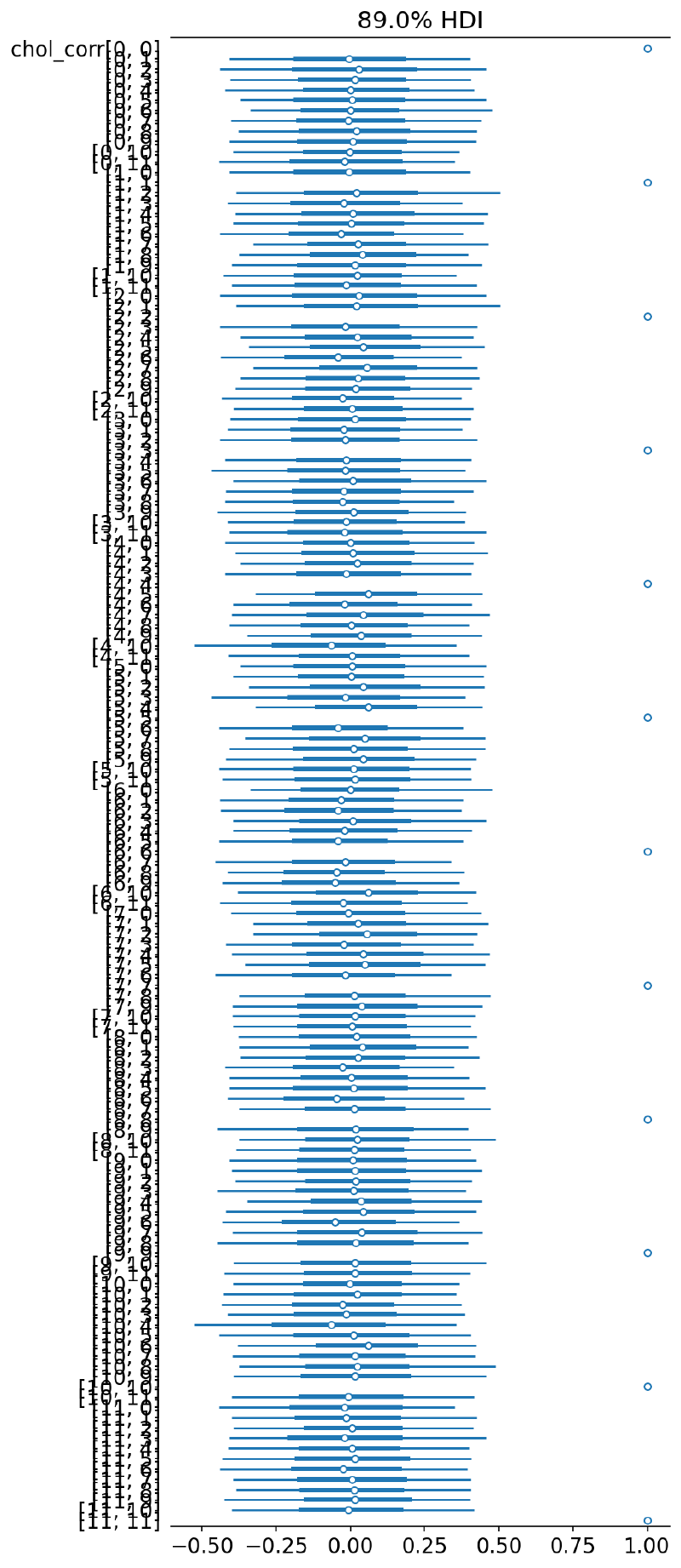
The posterior estimates for the correlation of the parameters in $\mathbf{w}$ are more interesting when there are multiple groups in the data. Data from multiple groups helps the multivariate normal identify the covariance between parameters of $\mathbf{w}$.
plot_chol_corr(m6_trace)/usr/local/Caskroom/miniconda/base/envs/speclet/lib/python3.9/site-packages/arviz/stats/diagnostics.py:561: RuntimeWarning: invalid value encountered in double_scalars
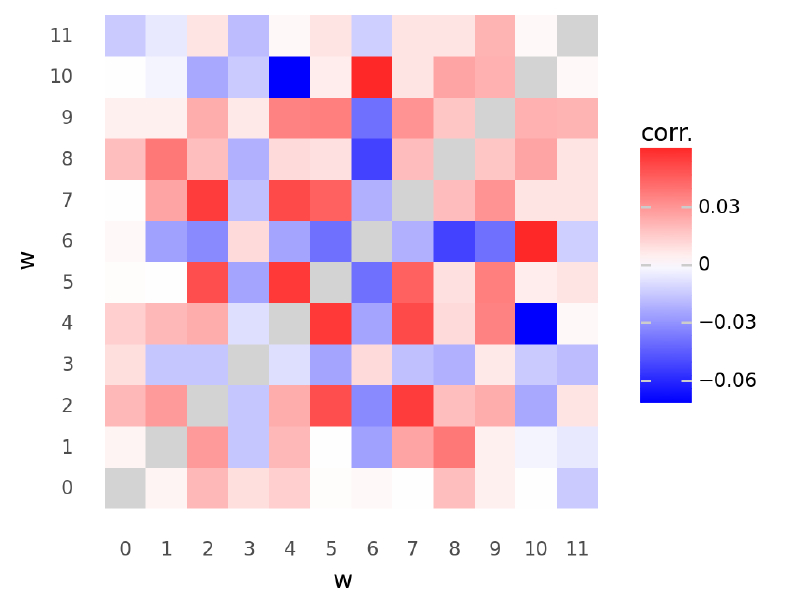
<ggplot: (336864627)>
az.plot_parallel(m6_trace, var_names="w")
plt.show()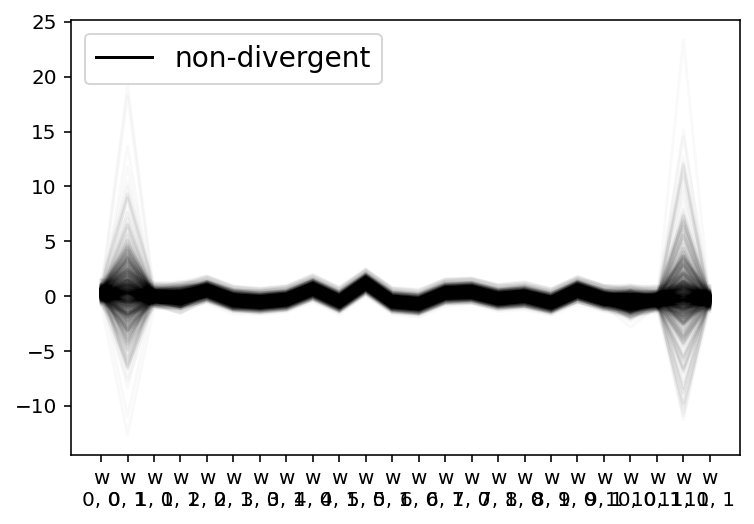
plot_posterior_mu(m6_trace, m3_data.data)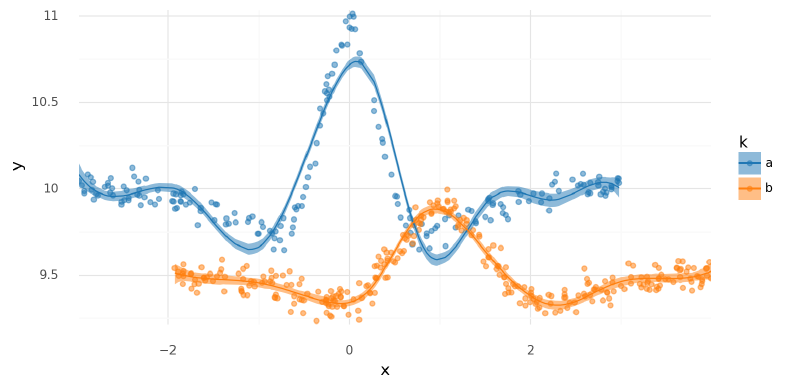
<ggplot: (338965917)>
summarize_and_plot_ppc(m6_trace, m3_data.data)/var/folders/r4/qpcdgl_14hbd412snp1jnv300000gn/T/ipykernel_16319/1935723833.py:5: FutureWarning: hdi currently interprets 2d data as (draw, shape) but this will change in a future release to (chain, draw) for coherence with other functions
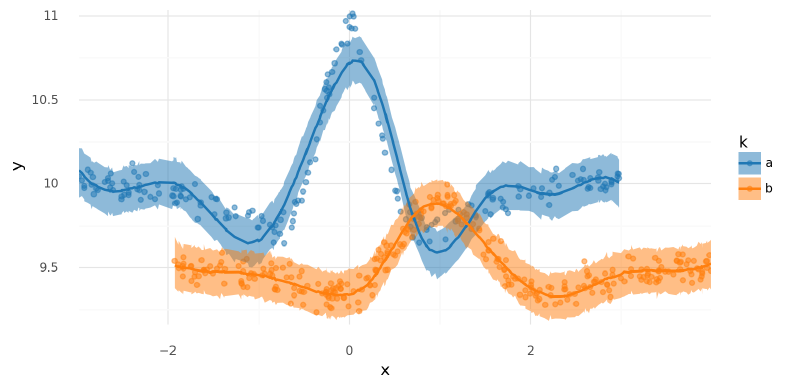
<ggplot: (339602279)>
Out-of-distribution predictions#
with build_model6(new_m3_data):
m6_post_pred_new = pm.sample_posterior_predictive(
trace=m6_trace,
var_names=["mu", "y"],
return_inferencedata=True,
extend_inferencedata=False,
)(
summarize_and_plot_ppc(m6_post_pred_new, new_m3_data.data, plot_pts=False)
+ gg.geom_point(gg.aes(x="x", y="y", color="k"), data=m3_data.data, size=0.1)
# + gg.scale_y_continuous(limits=(7.5, 12))
)/var/folders/r4/qpcdgl_14hbd412snp1jnv300000gn/T/ipykernel_16319/1935723833.py:5: FutureWarning: hdi currently interprets 2d data as (draw, shape) but this will change in a future release to (chain, draw) for coherence with other functions
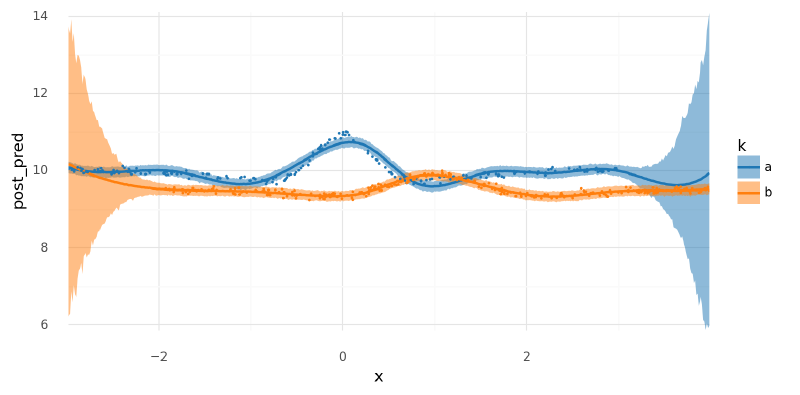
<ggplot: (340773346)>
Fitting model when the curves are more related#
One thing to note with the mock data used above is that the curves often moved in different directions in the most interesting parts of the curve (i.e. near the peaks). This made it difficult for the multivariate normal prior to identify consistent trends in the spline parameters $\mathbf{w}$ corresponding to these regions. To highlight the capabilities of the multivariate normal distribution, I built new mock data from sine curves of the same period but different amplitudes. These curves are far more correlated in structure, resulting in a more interesting correlation matrix.
np.random.seed(RANDOM_SEED)
groups = list("abcde")
amps = np.arange(4, 4 + len(groups))
m6_groups_data: list[pd.DataFrame] = []
for k, A in zip(groups, amps):
xmin, xmax = np.random.normal(0, 0.1), np.random.normal(2, 0.1)
n = int(np.random.normal(150, 5))
x = np.random.uniform(xmin, xmax, n)
y = A * np.sin(np.pi * x)
y_offset = np.random.uniform(-10, 10)
noise = np.random.normal(0, 0.4, n)
y = y + y_offset + noise
df = pd.DataFrame({"x": x, "y": y}).assign(k=k)
m6_groups_data.append(df)
m6_df = pd.concat(m6_groups_data).reset_index(drop=True)
m6_df["k"] = pd.Categorical(m6_df["k"], categories=groups, ordered=True)
m6_knots2, m6_B2 = build_spline(data=m6_df, intercept=True)
m6_data2 = ModelData(data=m6_df, B=m6_B2, knots=m6_knots2)
ax = sns.scatterplot(data=m6_data2.data, x="x", y="y", hue="k", palette=group_pal)
for knot in m6_data2.knots:
ax.axvline(knot, c="k", ls="--", lw=1)
ax.legend(loc="upper left", bbox_to_anchor=(1, 1))
plt.show()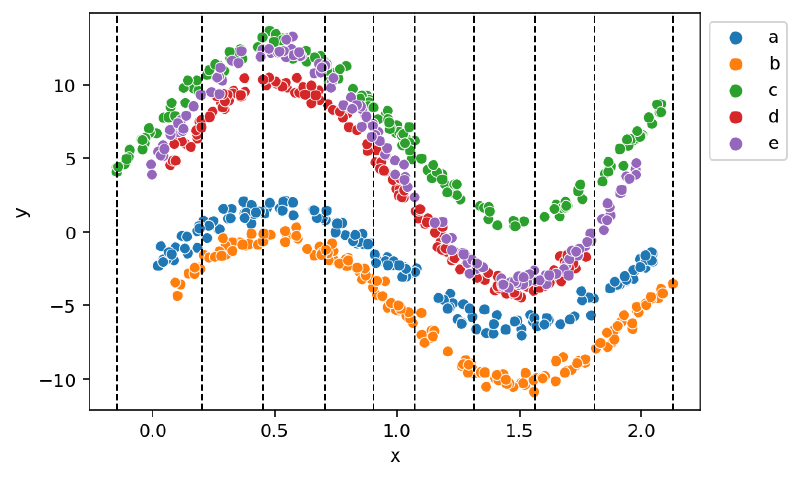
m6_2 = build_model6(m6_data2)
pm.model_to_graphviz(m6_2)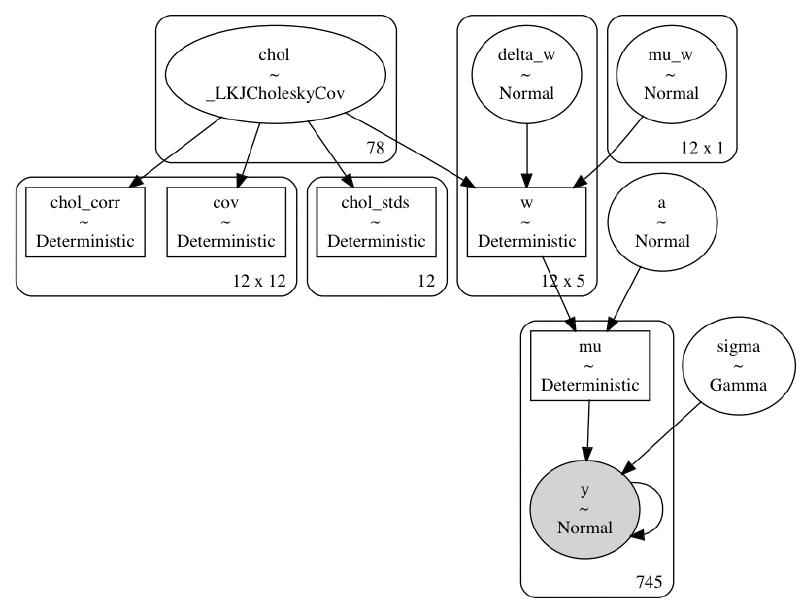
with m6_2:
m6_trace2 = pm.sample(**m6_sample_kwargs)
pm.sample_posterior_predictive(m6_trace2, **pm_ppc_kwargs)Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (2 chains in 2 jobs)
NUTS: [chol, mu_w, delta_w, a, sigma]
Sampling 2 chains for 500 tune and 500 draw iterations (1_000 + 1_000 draws total) took 519 seconds.
The chain reached the maximum tree depth. Increase max_treedepth, increase target_accept or reparameterize.
The chain reached the maximum tree depth. Increase max_treedepth, increase target_accept or reparameterize.
The estimated number of effective samples is smaller than 200 for some parameters.
az.plot_trace(m6_trace2, var_names=["a", "mu_w", "chol_stds", "w", "delta_w", "sigma"])
plt.tight_layout()
plt.show()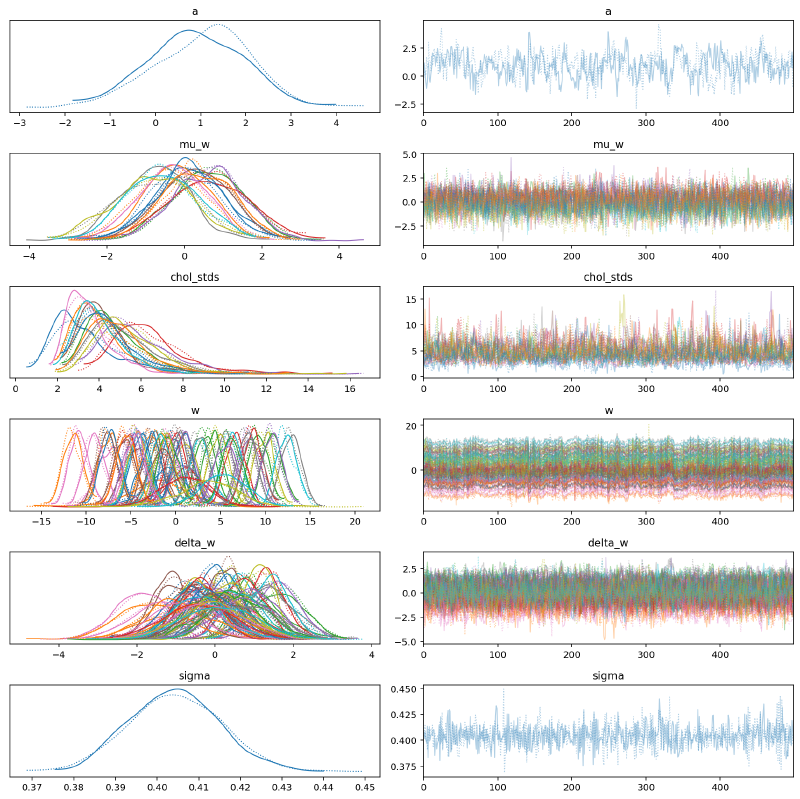
The parallel plot of $\mathbf{\mu_w}$ below shows that it detected the primary underlying form of the sine curves.
az.plot_parallel(m6_trace2, var_names=["mu_w"])
plt.show()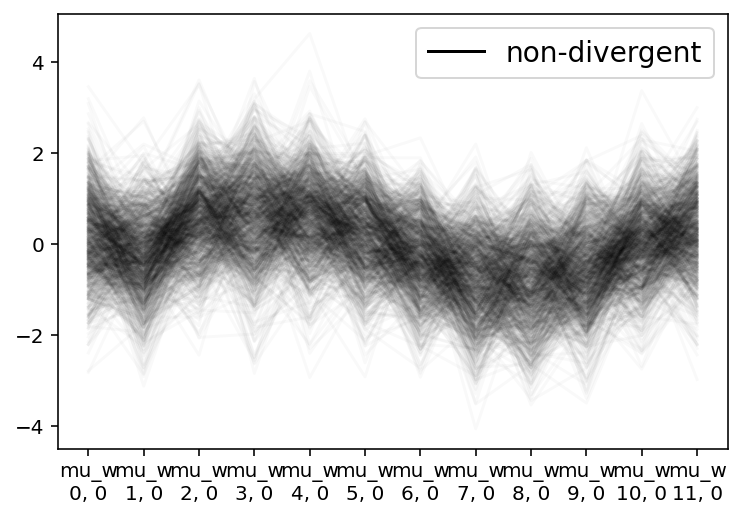
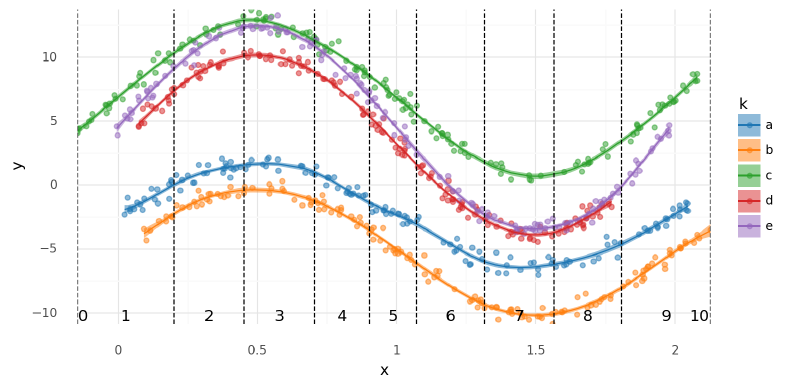
The model fit well and was able to make accurate posterior predictions. In the plot of the posterior of $\mu$ below, I also indicated the regions of the spline so that the following correlation matrix could be compared to the original data.
w_pos = [m6_data2.knots[0] + 0.02]
w_pos += ((m6_data2.knots[1:] + m6_data2.knots[:-1]) / 2).tolist()
w_pos.append(m6_data2.knots[-1] - 0.04)
knot_labels = pd.DataFrame({"x": w_pos, "label": np.arange(len(w_pos))})
(
plot_posterior_mu(m6_trace2, m6_data2.data)
+ gg.geom_vline(xintercept=m6_data2.knots, linetype="--")
+ gg.geom_text(
gg.aes(x="x", label="label"),
y=m6_data2.data.y.min(),
data=knot_labels,
va="bottom",
)
)
<ggplot: (340109496)>
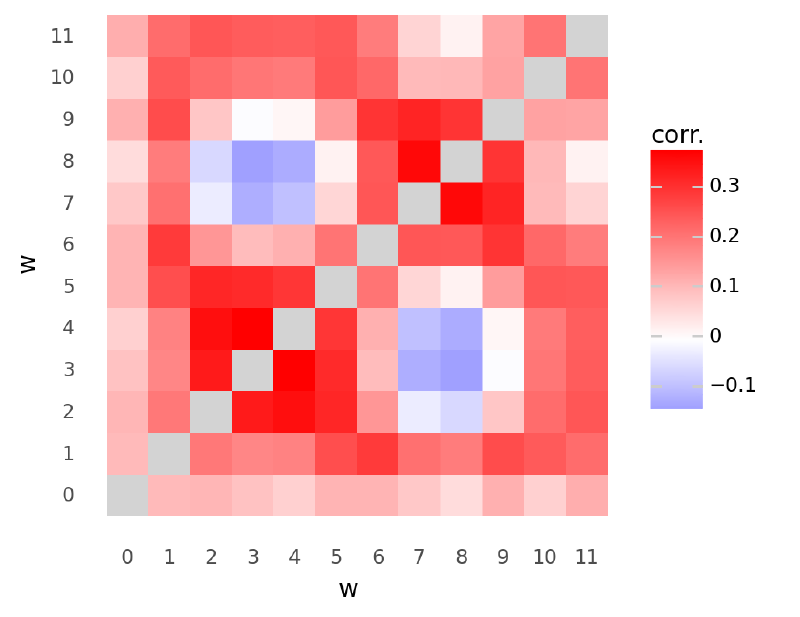
Note how spline parameters 3-4 and 7-8 were negatively correlated. The first set corresponded to a local maximum near $x=0.5$ and the latter to a local minimum around $x=1.5$.
plot_chol_corr(m6_trace2)/usr/local/Caskroom/miniconda/base/envs/speclet/lib/python3.9/site-packages/arviz/stats/diagnostics.py:561: RuntimeWarning: invalid value encountered in double_scalars
<ggplot: (341595627)>
axes = az.plot_forest(
m6_trace2,
var_names=["chol_corr"],
hdi_prob=HDI_PROB,
combined=True,
rope=[-0.1, 0.1],
)
for ax in axes.flatten():
ax.axvline(0, c="g")
plt.show()
summarize_and_plot_ppc(m6_trace2, m6_data2.data)/var/folders/r4/qpcdgl_14hbd412snp1jnv300000gn/T/ipykernel_16319/1935723833.py:5: FutureWarning: hdi currently interprets 2d data as (draw, shape) but this will change in a future release to (chain, draw) for coherence with other functions
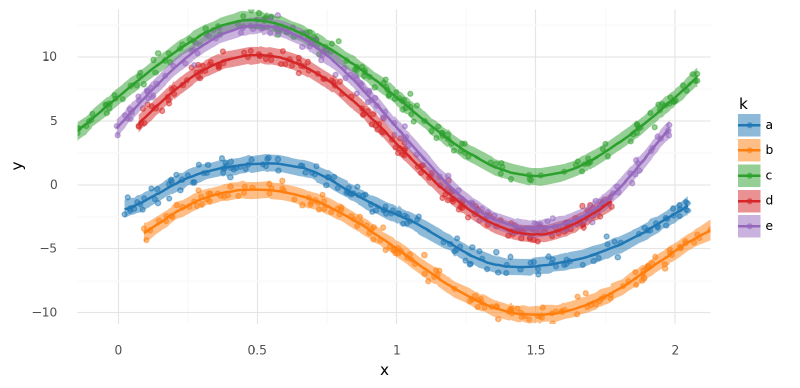
<ggplot: (340333635)>
Out-of-distribution predictions#
Lastly, I made predictions for each curve across the full observed region of $x$. Note how the partial pooling of the hierarchical structure affected each group differently.
new_m6_datas = []
for k in m6_data2.data.k.cat.categories:
new_data = build_new_data(m6_data2)
new_data.data["k"] = k
new_m6_datas.append(new_data)
new_m6_df = pd.concat([md.data for md in new_m6_datas]).reset_index(drop=True)
new_m6_df["k"] = pd.Categorical(
new_m6_df["k"], categories=m6_data2.data.k.cat.categories, ordered=True
)
_, new_m6_B = build_spline(new_m6_df, knot_list=m6_data2.knots, intercept=True)
new_m6_data2 = ModelData(data=new_m6_df, B=new_m6_B, knots=m6_data2.knots.copy())with build_model6(new_m6_data2):
m6_post_pred_new = pm.sample_posterior_predictive(
trace=m6_trace2,
var_names=["mu", "y"],
return_inferencedata=True,
extend_inferencedata=False,
)(
summarize_and_plot_ppc(m6_post_pred_new, new_m6_data2.data, plot_pts=False)
+ gg.geom_point(
gg.aes(x="x", y="y", color="k"), data=m6_data2.data, size=1, alpha=0.6
)
)/var/folders/r4/qpcdgl_14hbd412snp1jnv300000gn/T/ipykernel_16319/1935723833.py:5: FutureWarning: hdi currently interprets 2d data as (draw, shape) but this will change in a future release to (chain, draw) for coherence with other functions
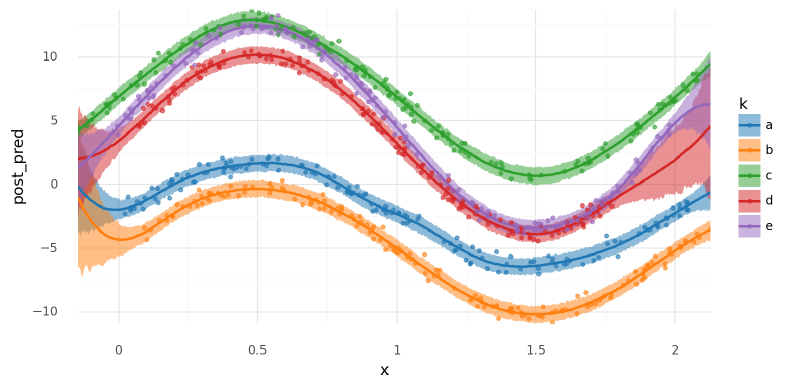
<ggplot: (341651658)>
Comments#
Adding the multivariate normal distribution to this model was a bit of a mixed bag. While on one hand it was a good addition in order to estimate the covariance between parameters of the spline, it simultaneously hurt the performance of MCMC.
Session info#
%load_ext watermark
%watermark -d -u -v -iv -b -h -mLast updated: 2022-02-25
Python implementation: CPython
Python version : 3.9.9
IPython version : 8.0.1
Compiler : Clang 11.1.0
OS : Darwin
Release : 21.3.0
Machine : x86_64
Processor : i386
CPU cores : 4
Architecture: 64bit
Hostname: JHCookMac
Git branch: add-nb-model
numpy : 1.22.2
janitor : 0.22.0
pymc : 4.0.0b2
pandas : 1.4.1
re : 2.2.1
aesara : 2.3.8
arviz : 0.11.4
plotnine : 0.8.0
matplotlib: 3.5.1
scipy : 1.7.3
seaborn : 0.11.2