Introduction#
Often, the model we want to fit is not a perfect line between some $x$ and $y$. Instead, the parameters of the model are expected to vary over $x$. There are multiple ways to handle this situation, one of which is to fit a spline. The spline is effectively multiple individual lines, each fit to a different section of $x$, that are tied together at their boundaries, often called knots. Below is an example of how to fit a spline using the Bayesian framework PyMC.
Fitting a spline with PyMC3#
Below is a full working example of how to fit a spline using the probabilistic programming language PyMC (v4.0.0b2). The data and model are taken from Statistical Rethinking 2e by Richard McElreath. As the book uses Stan (another advanced probabilistic programming language), the modeling code is primarily taken from the GitHub repository of the PyMC3 implementation of Statistical Rethinking. My contributions are primarily of explanation and additional analyses of the data and results.
Set-up#
Below is the code to import packages and set some variables used in the analysis. Most of the libraries and modules are likely familiar to many. Of those that may not be well known are ‘ArviZ’, ‘patsy’, and ‘plotnine’. ‘ArviZ’ is a library for managing the components of a Bayesian model. I will use it to manage the results of fitting the model and some standard data visualizations. The ‘patsy’ library is an interface to statistical modeling using a specific formula language similar to that used in the R language. Finally, ‘plotnine’ is a plotting library that implements the “Grammar or Graphics” system based on the ‘ggplot2’ R package. As I have a lot of experience with R, I found ‘plotnine’ far more natural than the “standard” in Python data science, ‘matplotlib’.
from pathlib import Path
import arviz as az
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import plotnine as gg
import pymc as pm
import seaborn as sns
from patsy import dmatrix
# Set default theme for 'plotnine'.
gg.theme_set(gg.theme_minimal())
# For reproducibility.
RANDOM_SEED = 847
np.random.seed(RANDOM_SEED)
# Path to the data used in Statistical Rethinking.
rethinking_data_path = Path("../data/rethinking_data")Data#
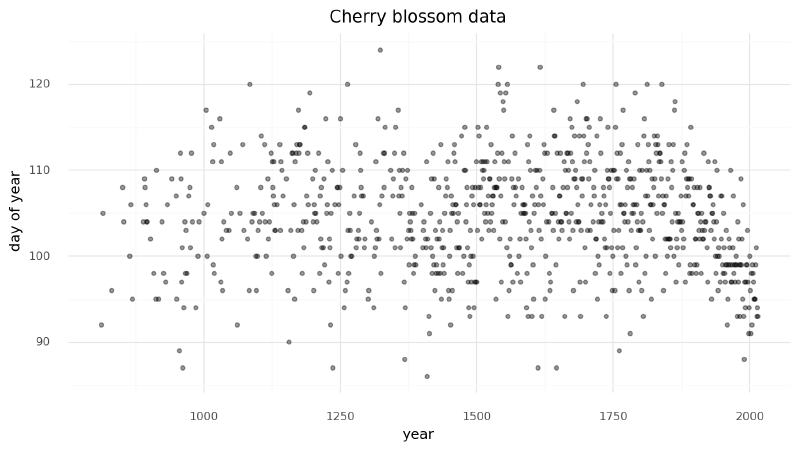
The data for this example was the first day of the year (doy) that the cherry trees bloomed in each year (year).
Years missing a doy were dropped.
d = pd.read_csv(rethinking_data_path / "cherry_blossoms.csv")
d2 = d.dropna(subset=["doy"]).reset_index(drop=True)
d2.head(n=10)| year | doy | temp | temp_upper | temp_lower | |
|---|---|---|---|---|---|
| 0 | 812 | 92 | nan | nan | nan |
| 1 | 815 | 105 | nan | nan | nan |
| 2 | 831 | 96 | nan | nan | nan |
| 3 | 851 | 108 | 7.38 | 12.1 | 2.66 |
| 4 | 853 | 104 | nan | nan | nan |
| 5 | 864 | 100 | 6.42 | 8.69 | 4.14 |
| 6 | 866 | 106 | 6.44 | 8.11 | 4.77 |
| 7 | 869 | 95 | nan | nan | nan |
| 8 | 889 | 104 | 6.83 | 8.48 | 5.19 |
| 9 | 891 | 109 | 6.98 | 8.96 | 5 |
There are 827 years with doy data.
>>> d2.shape
(827, 5)Below is the doy values plotted over year.
(
gg.ggplot(d2, gg.aes(x="year", y="doy"))
+ gg.geom_point(color="black", alpha=0.4, size=1.3)
+ gg.theme(figure_size=(10, 5))
+ gg.labs(x="year", y="day of year", title="Cherry blossom data")
)
Model#
We will fit the following model.
$D \sim \mathcal{N}(\mu, \sigma)$
$\quad \mu = a + Bw$
$\qquad a \sim \mathcal{N}(100, 10)$
$\qquad w \sim \mathcal{N}(0, 10)$
$\quad \sigma \sim \text{Exp}(1)$
The day of first bloom will be modeled as a normal distribution with mean $\mu$ and standard deviation $\sigma$. The mean will be a linear model composed of a y-intercept $a$ and spline defined by the basis $B$ multiplied by the model parameter $w$ with a variable for each region of the basis. Both have relatively weak normal priors.
Prepare the spline#
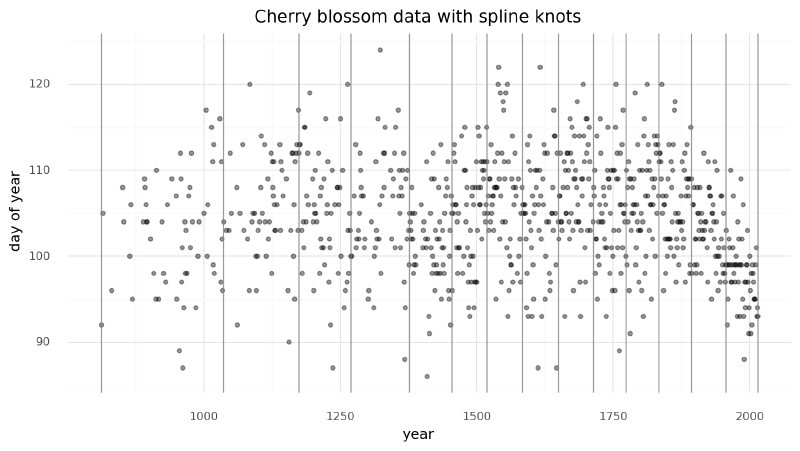
We can now prepare the spline matrix. First, we must determine the boundaries of the spline, often referred to as “knots” because the individual lines will be tied together at these boundaries to make a continuous and smooth curve. For this example, we will create 15 knots unevenly spaced over the years such that each region will have the same proportion of data.
num_knots = 15
knot_list = np.quantile(d2.year, np.linspace(0, 1, num_knots))>>> knot_list
array([ 812., 1036., 1174., 1269., 1377., 1454., 1518., 1583., 1650.,
1714., 1774., 1833., 1893., 1956., 2015.])Below is the plot of the data we are modeling with the splines indicated by the vertical gray lines.
(
gg.ggplot(d2, gg.aes(x="year", y="doy"))
+ gg.geom_point(color="black", alpha=0.4, size=1.3)
+ gg.geom_vline(xintercept=knot_list, color="gray", alpha=0.8)
+ gg.theme(figure_size=(10, 5))
+ gg.labs(x="year", y="day of year", title="Cherry blossom data with spline knots")
)
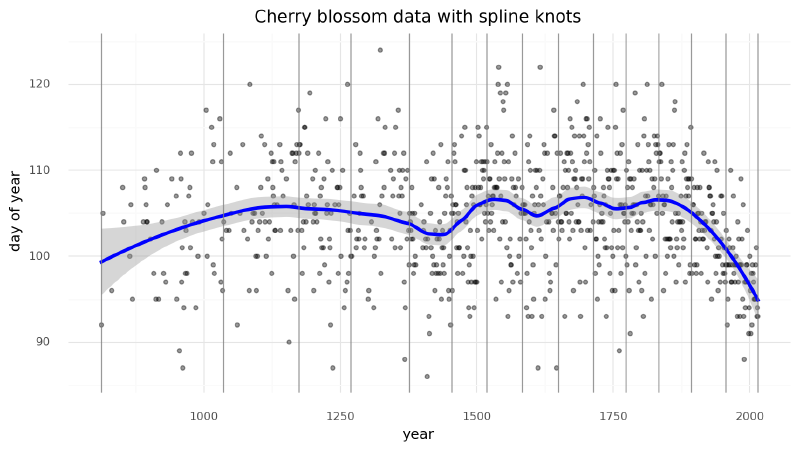
We can get an idea of what the spline will look like by fitting a LOESS curve (a local polynomial regression).
(
gg.ggplot(d2, gg.aes(x="year", y="doy"))
+ gg.geom_point(color="black", alpha=0.4, size=1.3)
+ gg.geom_smooth(method="loess", span=0.3, size=1.5, color="blue", linetype="-")
+ gg.geom_vline(xintercept=knot_list, color="gray", alpha=0.8)
+ gg.theme(figure_size=(10, 5))
+ gg.labs(x="year", y="day of year", title="Cherry blossom data with spline knots")
)
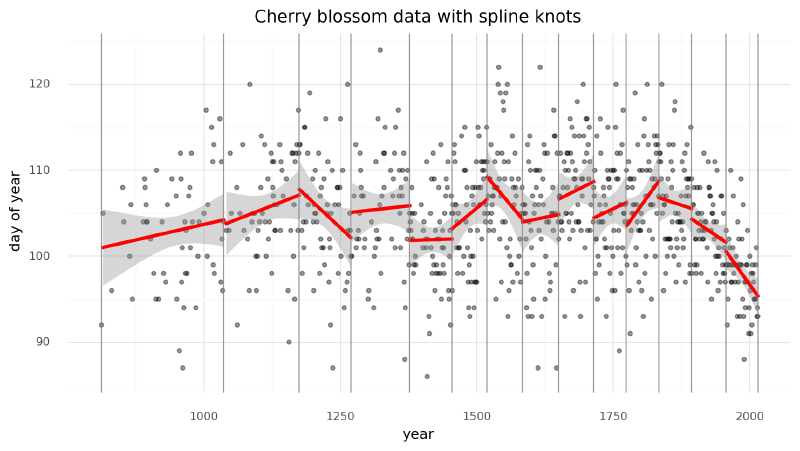
Another way of visualizing what the spline should look like is to plot individual linear models over the data between each knot. The spline will effectively be a compromise between these individual models and a continuous curve.
d2["knot_group"] = [np.where(a <= knot_list)[0][0] for a in d2.year]
d2["knot_group"] = pd.Categorical(d2["knot_group"], ordered=True)
(
gg.ggplot(d2, gg.aes(x="year", y="doy"))
+ gg.geom_point(color="black", alpha=0.4, size=1.3)
+ gg.geom_smooth(
gg.aes(group="knot_group"), method="lm", size=1.5, color="red", linetype="-"
)
+ gg.geom_vline(xintercept=knot_list, color="gray", alpha=0.8)
+ gg.theme(figure_size=(10, 5))
+ gg.labs(x="year", y="day of year", title="Cherry blossom data with spline knots")
)
Finally we can use ‘patsy’ to create the matrix $B$ that will be the b-spline basis for the regression. The degree is set to 3 to create a cubic b-spline.
B = dmatrix(
"bs(year, knots=knots, degree=3, include_intercept=True) - 1",
{"year": d2.year.values, "knots": knot_list[1:-1]},
)>>> B
DesignMatrix with shape (827, 17)
Columns:
['bs(year, knots=knots, degree=3, include_intercept=True)[0]',
'bs(year, knots=knots, degree=3, include_intercept=True)[1]',
'bs(year, knots=knots, degree=3, include_intercept=True)[2]',
'bs(year, knots=knots, degree=3, include_intercept=True)[3]',
'bs(year, knots=knots, degree=3, include_intercept=True)[4]',
'bs(year, knots=knots, degree=3, include_intercept=True)[5]',
'bs(year, knots=knots, degree=3, include_intercept=True)[6]',
'bs(year, knots=knots, degree=3, include_intercept=True)[7]',
'bs(year, knots=knots, degree=3, include_intercept=True)[8]',
'bs(year, knots=knots, degree=3, include_intercept=True)[9]',
'bs(year, knots=knots, degree=3, include_intercept=True)[10]',
'bs(year, knots=knots, degree=3, include_intercept=True)[11]',
'bs(year, knots=knots, degree=3, include_intercept=True)[12]',
'bs(year, knots=knots, degree=3, include_intercept=True)[13]',
'bs(year, knots=knots, degree=3, include_intercept=True)[14]',
'bs(year, knots=knots, degree=3, include_intercept=True)[15]',
'bs(year, knots=knots, degree=3, include_intercept=True)[16]']
Terms:
'bs(year, knots=knots, degree=3, include_intercept=True)' (columns 0:17)
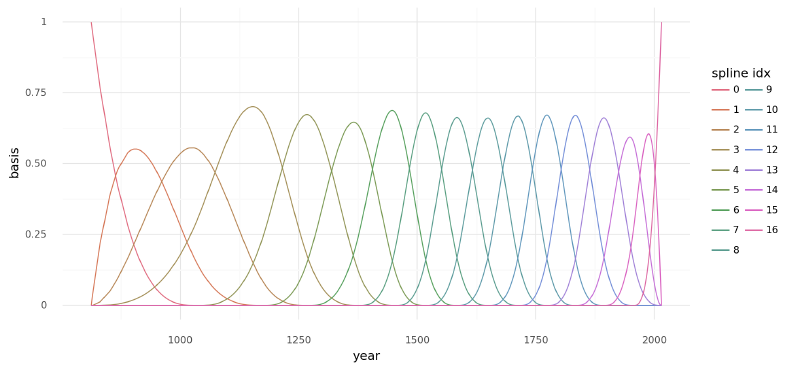
(to view full data, use np.asarray(this_obj))The b-spline basis is plotted below, showing the “domain” of each piece of the spline. The height of each curve indicates how influential the corresponding model covariate (one per spline region) will be on the final model. The overlapping regions represent the knots showing how the smooth transition from one region to the next is formed.
spline_df = (
pd
.DataFrame(B)
.assign(year=d2.year.values)
.melt("year", var_name="spline_i", value_name="value")
)
(
gg.ggplot(spline_df, gg.aes(x="year", y="value"))
+ gg.geom_line(gg.aes(group="spline_i", color="spline_i"))
+ gg.scale_color_discrete(guide=gg.guide_legend(ncol=2))
+ gg.labs(x="year", y="basis", color="spline idx")
)
Fitting#
Finally, the model can be built using PyMC. A graphical diagram shows the organization of the model parameters.
with pm.Model(rng_seeder=RANDOM_SEED) as m4_7:
a = pm.Normal("a", 100, 5)
w = pm.Normal("w", mu=0, sd=3, shape=B.shape[1])
mu = pm.Deterministic("mu", a + pm.math.dot(np.asarray(B, order="F"), w.T))
sigma = pm.Exponential("sigma", 1)
D = pm.Normal("D", mu, sigma, observed=d2.doy)pm.model_to_graphviz(m4_7)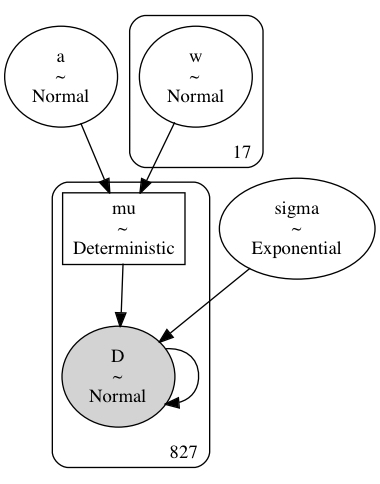
2000 samples of the posterior distribution are taken and the posterior predictions are calculated.
with m4_7:
trace_m4_7 = pm.sample(2000, tune=2000, chains=2, return_inferencedata=True)
_ = pm.sample_posterior_predictive(trace_m4_7, extend_inferencedata=True)Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (2 chains in 2 jobs)
NUTS: [a, w, sigma]100.00% [8000/8000 00:41<00:00 Sampling 2 chains, 0 divergences]
Sampling 2 chains for 2_000 tune and 2_000 draw iterations (4_000 + 4_000 draws total) took 57 seconds.100.00% [4000/4000 00:00<00:00]Analysis#
Now we can analyze the draws from the posterior of the model.
Fit parameters#
Below is a table summarizing the posterior distributions of the model parameters. The posteriors of $a$ and $\sigma$ are quite narrow while those for $w$ are wider. This is likely because all of the data points are used to estimate $a$ and $\sigma$ whereas only a subset are used for each value of $w$. (It could be interesting to model these hierarchically allowing for the sharing of information and adding regularization across the spline.) The effective sample size and $\widehat{R}$ values all look good, indicating that the model has converged and sampled well from the posterior distribution.
az.summary(trace_m4_7, var_names=["a", "w", "sigma"])| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| a | 103.651 | 0.755 | 102.296 | 105.120 | 0.018 | 0.013 | 1691.0 | 1572.0 | 1.0 |
| w[0] | -1.795 | 2.202 | -6.027 | 2.212 | 0.037 | 0.031 | 3496.0 | 2923.0 | 1.0 |
| w[1] | -1.654 | 2.057 | -5.351 | 2.409 | 0.037 | 0.027 | 3028.0 | 2949.0 | 1.0 |
| w[2] | -0.252 | 1.935 | -4.041 | 3.326 | 0.035 | 0.026 | 3042.0 | 2976.0 | 1.0 |
| w[3] | 3.326 | 1.481 | 0.632 | 6.144 | 0.029 | 0.020 | 2632.0 | 2603.0 | 1.0 |
| w[4] | 0.204 | 1.512 | -2.574 | 3.114 | 0.027 | 0.020 | 3063.0 | 2893.0 | 1.0 |
| w[5] | 2.104 | 1.635 | -1.024 | 5.124 | 0.031 | 0.022 | 2818.0 | 2936.0 | 1.0 |
| w[6] | -3.561 | 1.472 | -6.320 | -0.720 | 0.025 | 0.018 | 3349.0 | 3466.0 | 1.0 |
| w[7] | 5.536 | 1.422 | 2.802 | 8.075 | 0.027 | 0.019 | 2787.0 | 3028.0 | 1.0 |
| w[8] | -0.067 | 1.512 | -2.861 | 2.788 | 0.026 | 0.019 | 3322.0 | 3377.0 | 1.0 |
| w[9] | 2.227 | 1.561 | -0.665 | 5.200 | 0.029 | 0.021 | 2973.0 | 3255.0 | 1.0 |
| w[10] | 3.766 | 1.485 | 0.909 | 6.471 | 0.029 | 0.020 | 2681.0 | 2929.0 | 1.0 |
| w[11] | 0.311 | 1.493 | -2.428 | 3.196 | 0.028 | 0.021 | 2917.0 | 2911.0 | 1.0 |
| w[12] | 4.143 | 1.537 | 1.292 | 7.047 | 0.030 | 0.021 | 2574.0 | 2562.0 | 1.0 |
| w[13] | 1.077 | 1.601 | -1.686 | 4.270 | 0.030 | 0.021 | 2938.0 | 3144.0 | 1.0 |
| w[14] | -1.818 | 1.795 | -4.994 | 1.719 | 0.035 | 0.025 | 2665.0 | 2802.0 | 1.0 |
| w[15] | -5.979 | 1.834 | -9.503 | -2.679 | 0.032 | 0.023 | 3262.0 | 2979.0 | 1.0 |
| w[16] | -6.190 | 1.876 | -9.943 | -2.839 | 0.032 | 0.023 | 3370.0 | 2896.0 | 1.0 |
| sigma | 5.954 | 0.145 | 5.684 | 6.230 | 0.002 | 0.001 | 5054.0 | 3315.0 | 1.0 |
We can visualize the trace (MCMC samples) of the parameters, again showing they were confidently estimated.
az.plot_trace(trace_m4_7, var_names=["a", "w", "sigma"])
plt.tight_layout()
plt.show()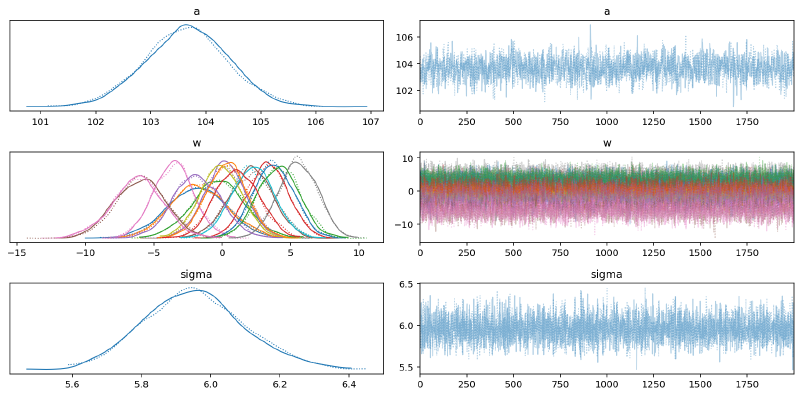
A forest plot shows the distributions of the values for $w$ are larger, though some do fall primarily away from 0 indicating a non-null effect/association.
az.plot_forest(trace_m4_7, var_names=["w"], combined=True)
plt.show()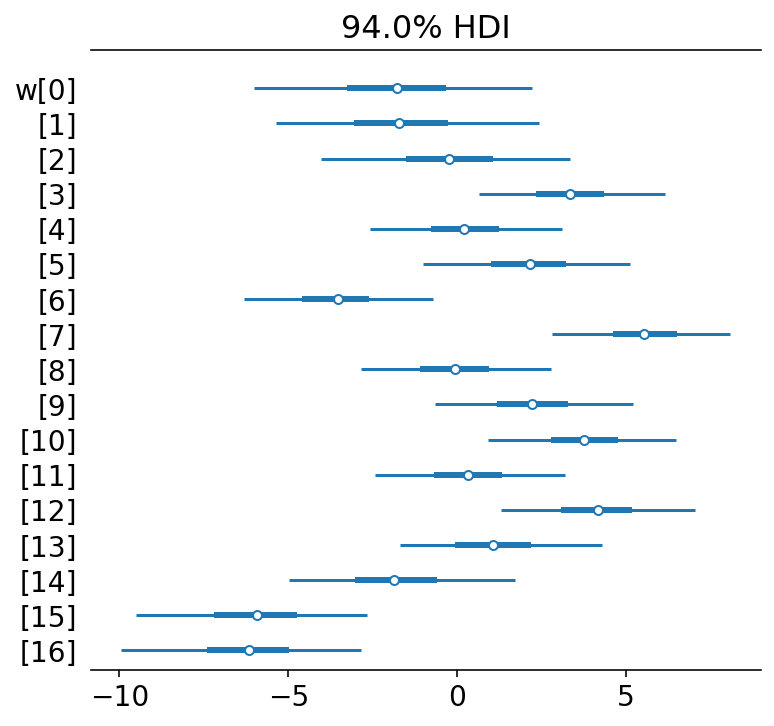
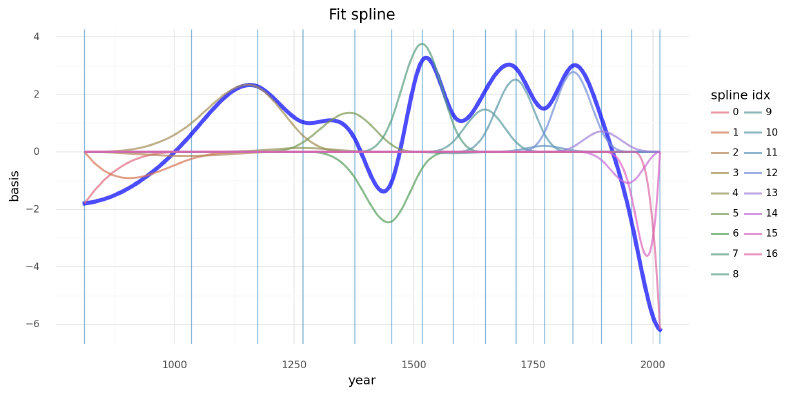
Another visualization of the fit spline values is to plot them multiplied against the basis matrix. The knot boundaries are shown in gray again, but now the spline basis is multiplied against the values of $w$ (represented as the rainbow-colored curves). The dot product of $B$ and $w$ - the actual computation in the linear model - is shown in blue.
wp = trace_m4_7.posterior["w"].values.mean(axis=(0, 1))
spline_df = (
pd
.DataFrame(B * wp.T)
.assign(year=d2.year.values)
.melt("year", var_name="spline_i", value_name="value")
)
spline_df_merged = (
pd
.DataFrame(np.dot(B, wp.T))
.assign(year=d2.year.values)
.melt("year", var_name="spline_i", value_name="value")
)
(
gg.ggplot(spline_df, gg.aes(x="year", y="value"))
+ gg.geom_vline(xintercept=knot_list, color="#0C73B4", alpha=0.5)
+ gg.geom_line(data=spline_df_merged, linetype="-", color="blue", size=2, alpha=0.7)
+ gg.geom_line(gg.aes(group="spline_i", color="spline_i"), alpha=0.7, size=1)
+ gg.scale_color_discrete(guide=gg.guide_legend(ncol=2), color_space="husl")
+ gg.theme(figure_size=(10, 5))
+ gg.labs(x="year", y="basis", title="Fit spline", color="spline idx")
)
Model predictions#
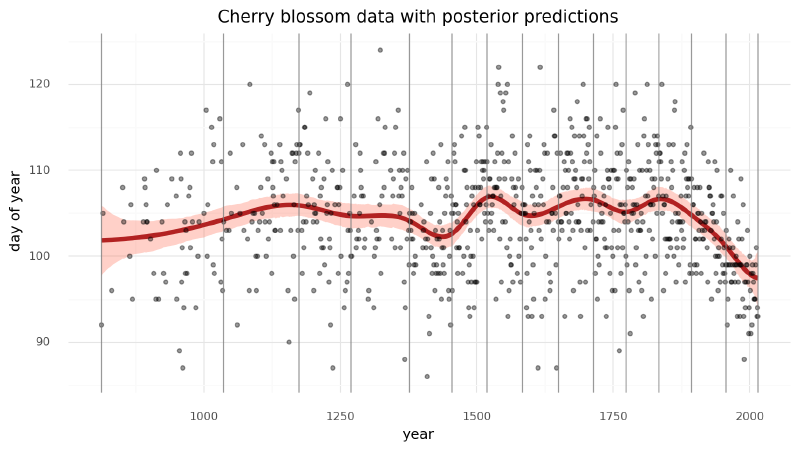
Lastly, we can visualize the predictions of the model using the posterior predictive check.
post_pred = az.summary(trace_m4_7, var_names=["mu"]).reset_index(drop=True)
d2_post = d2.copy().reset_index(drop=True)
d2_post["pred_mean"] = post_pred["mean"]
d2_post["pred_hdi_lower"] = post_pred["hdi_3%"]
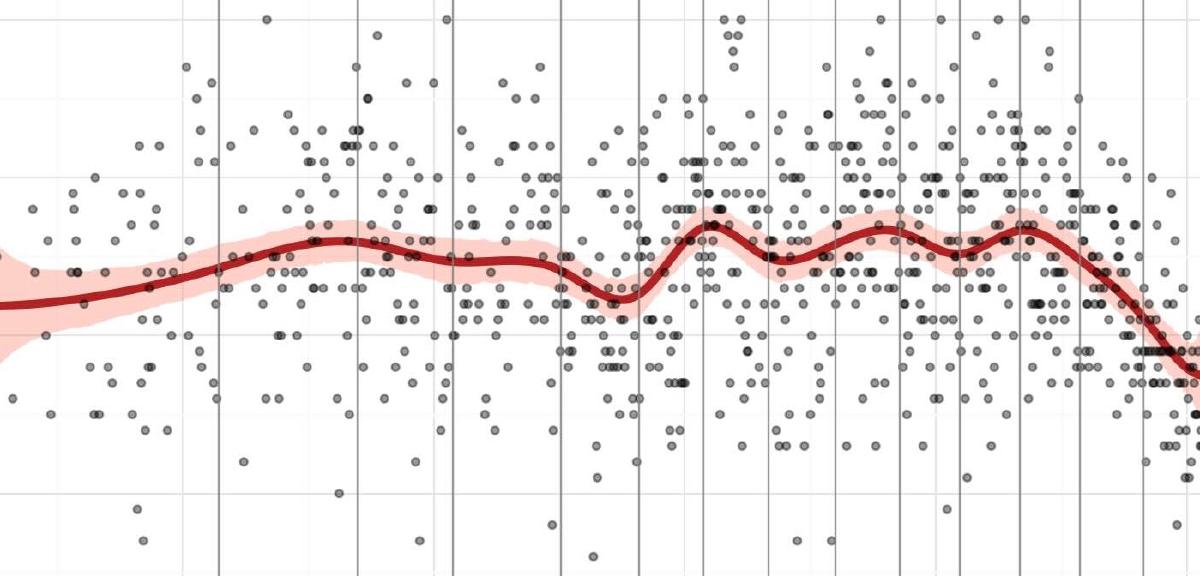
d2_post["pred_hdi_upper"] = post_pred["hdi_97%"](
gg.ggplot(d2_post, gg.aes(x="year"))
+ gg.geom_ribbon(
gg.aes(ymin="pred_hdi_lower", ymax="pred_hdi_upper"), alpha=0.3, fill="tomato"
)
+ gg.geom_line(gg.aes(y="pred_mean"), color="firebrick", alpha=1, size=2)
+ gg.geom_point(gg.aes(y="doy"), color="black", alpha=0.4, size=1.3)
+ gg.geom_vline(xintercept=knot_list, color="gray", alpha=0.8)
+ gg.theme(figure_size=(10, 5))
+ gg.labs(
x="year",
y="day of year",
title="Cherry blossom data with posterior predictions",
)
)
Updates#
2022-03-12#
It was pointed out to me by a reader that doy was not the number of days of bloom, but the day of the year with the first bloom.
I fixed this in the text and plots.
I also took this opportunity to fix the embarrassingly large number of typos and update the code to use PyMC v4.